Por que apenas algumas das páginas do meu site estão sendo rastreadas?
Se você notou que apenas 4 a 6 páginas do seu site estão sendo rastreadas (sua página inicial, URLs de sitemaps e robots.txt), provavelmente é porque nosso bot não conseguiu encontrar links internos de saída na página inicial. Confira abaixo as possíveis razões para esse problema.
Talvez não haja links internos de saída em sua página principal, ou eles podem estar incluídos no JavaScript. Nosso bot analisa o conteúdo do JavaScript somente nos planos Guru e Business do Kit de ferramentas de SEO. Portanto, se você não tiver o plano Guru ou Business e sua página inicial tiver links para outras partes do seu site dentro de elementos JavaScript, não vamos detectar nem rastrear essas páginas.
Embora o rastreamento de JavaScript esteja disponível apenas nos planos Guru e Business, ainda podemos rastrear o HTML de páginas que contêm elementos JavaScript. Além disso, nossas verificações de desempenho podem avaliar os parâmetros dos seus arquivos JavaScript e CSS, não importa qual seja o plano de assinatura.
Em ambos os casos, há uma maneira de garantir que nosso bot rastreie suas páginas. Para fazer isso, você precisa alterar “Páginas a rastrear” de “Site” para “Sitemap” ou “URLs do arquivo” nas configurações da campanha:
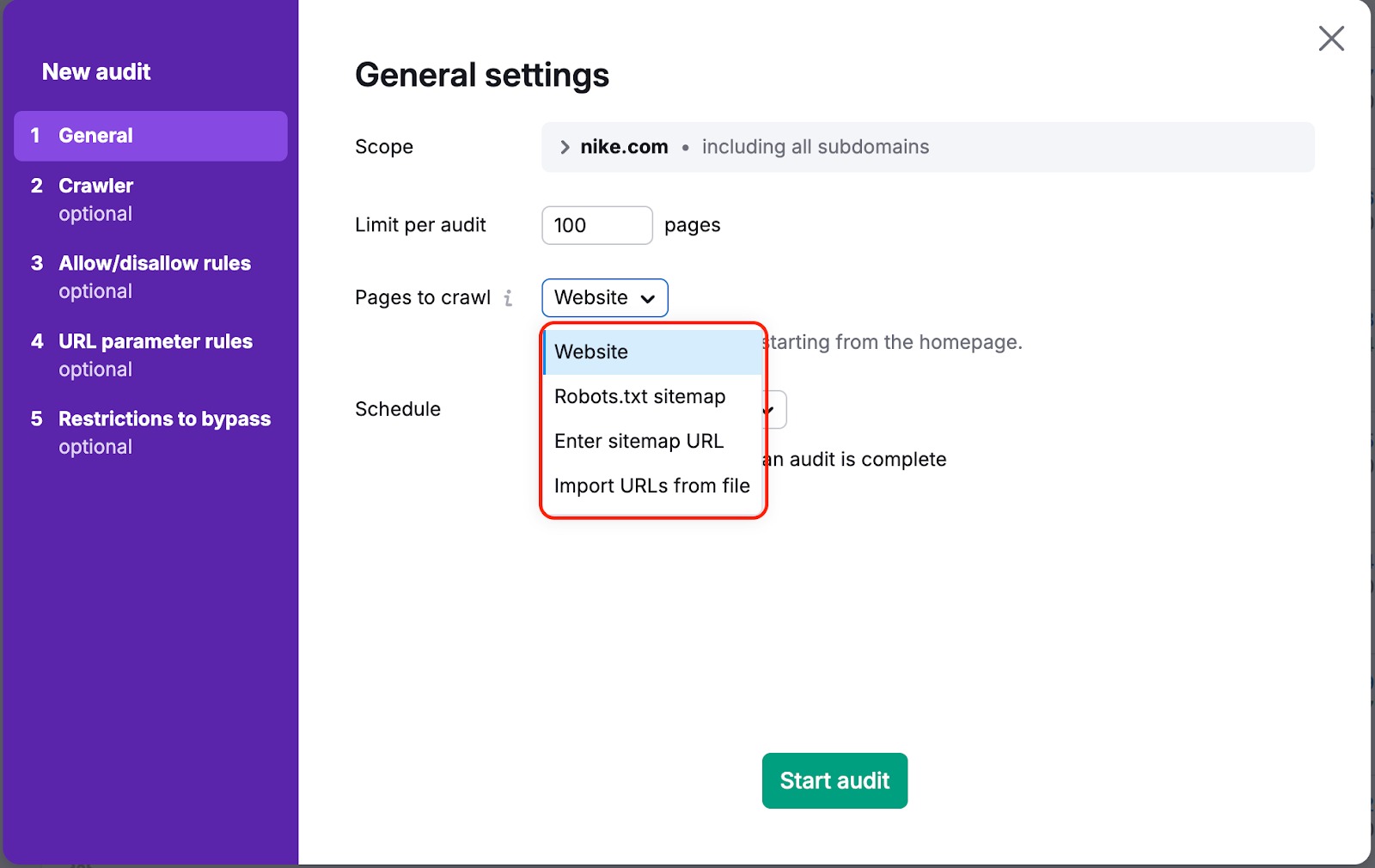
“Site” é a fonte padrão. Isso significa que vamos rastrear seu site usando um algoritmo de pesquisa em largura (breadth-first) e navegando pelos links que encontrarmos no código da sua página, começando pela página inicial.
Se você escolher uma das outras opções, rastrearemos os links encontrados no sitemap ou no arquivo enviado.
Nosso rastreador pode ter sido bloqueado em algumas páginas no robots.txt do site ou por tags noindex/nofollow. Você pode verificar se esse é o caso no relatório de páginas rastreadas:
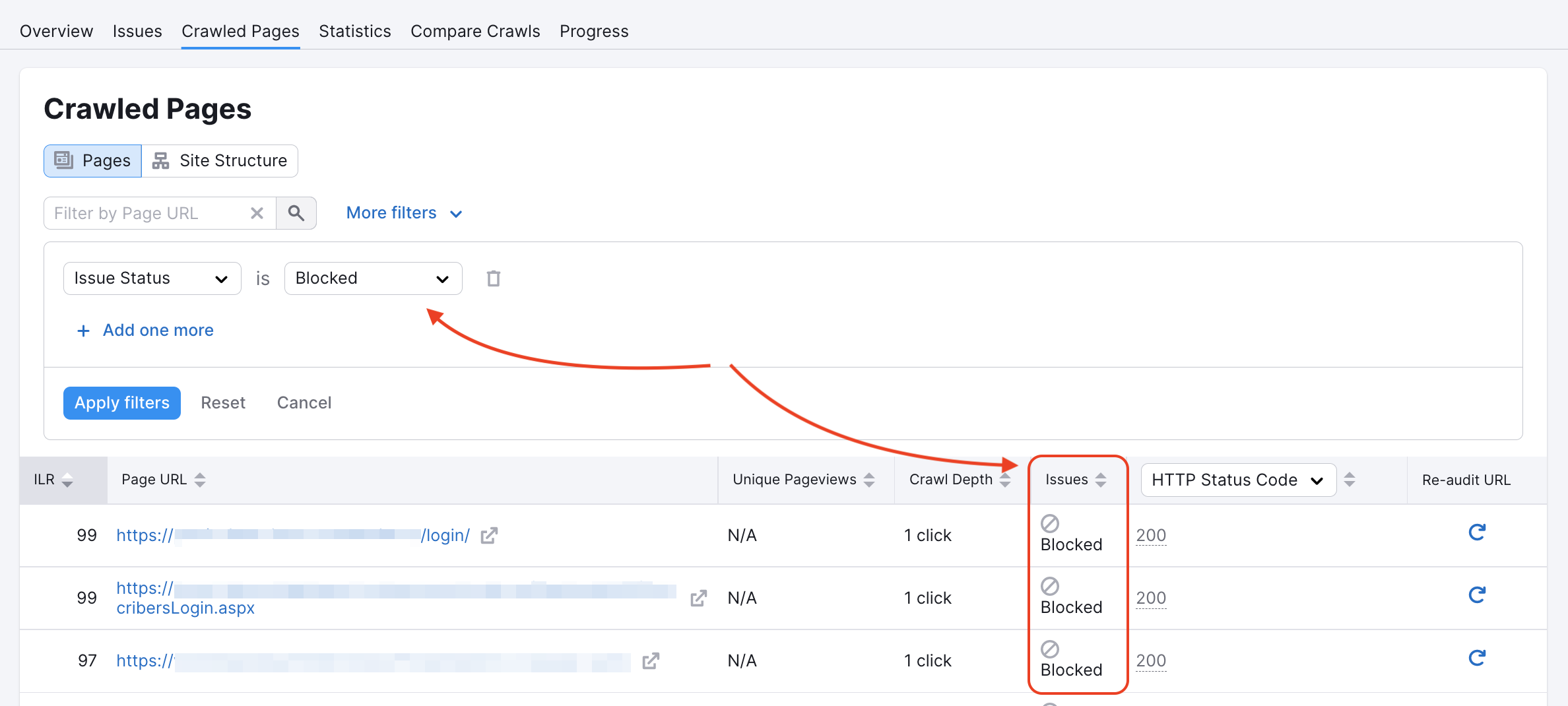
Você pode inspecionar o arquivo robots.txt em busca de quaisquer comandos de disallow que impeçam rastreadores como o nosso de acessar seu site.
Se o código abaixo estiver presente na página principal de um site, ele indica ao nosso rastreador que não temos permissão para indexar/seguir links nele e que nosso acesso está bloqueado. Ou uma página contendo pelo menos uma das tags "nofollow" ou "none" levará a um erro de rastreamento.
Confira mais informações sobre esses erros em nosso artigo de solução de problemas.
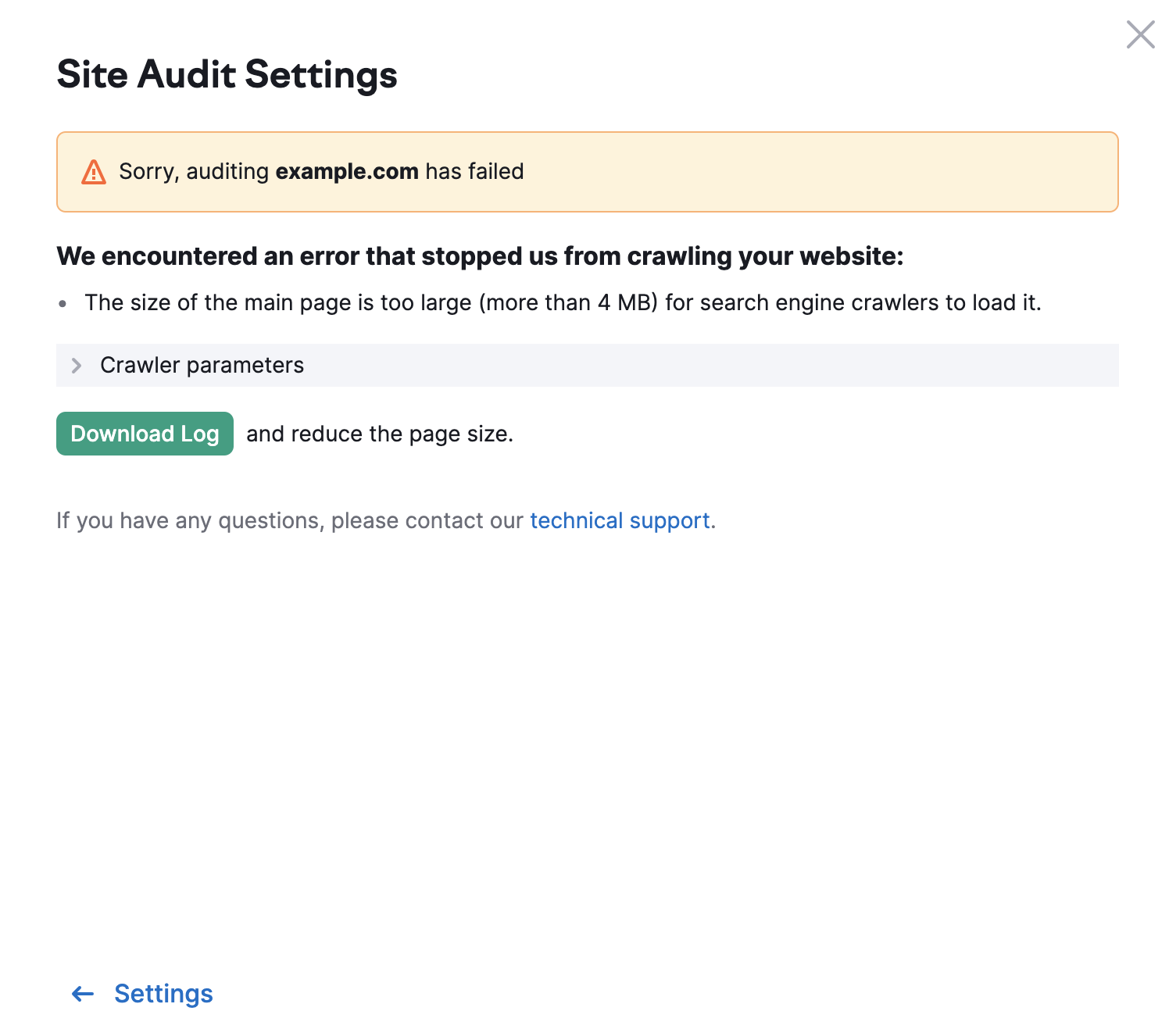
O limite para outras páginas do seu site é de 2 MB. Caso uma página tenha um HTML de tamanho muito grande, será exibido o seguinte erro:
