A Auditoria do site não está funcionando corretamente?
Existem vários motivos pelos quais as páginas podem ser bloqueadas para o rastreador de Auditoria do site com base na configuração e estrutura do seu site, incluindo:
- O robots.txt bloqueia os rastreadores
- O escopo do rastreamento exclui certas áreas do site
- O site não está online diretamente devido à hospedagem compartilhada
- O tamanho da página de destino excede 2 MB
- As páginas estão atrás de um gateway/área do site com acesso via usuário/senha
- A tag noindex bloqueia os rastreadores
- O domínio não pôde ser resolvido pelo DNS – o domínio inserido na configuração está offline
- Conteúdo do site criado em JavaScript – embora a Auditoria do site consiga renderizar código JS, esse pode ser o motivo de alguns problemas
Etapas de solução de problemas
Siga estas etapas de solução de problemas para ver se você pode fazer ajustes por conta própria antes de entrar em contato com nossa equipe de suporte para solicitar ajuda.
O arquivo robots.txt dá instruções aos bots sobre como rastrear (ou não rastrear) as páginas de um site. Você pode permitir e proibir bots como o Googlebot ou Semrushbot de rastrear todo o seu site ou áreas específicas usando comandos como Allow, Disallow, e Crawl Delay.
Se o robots.txt estiver impedindo nosso bot de rastrear o seu site, a ferramenta Auditoria do site não conseguirá verificar o site.
Você pode inspecionar o arquivo robots.txt em busca de quaisquer comandos de disallow que impeçam rastreadores como o nosso de acessar seu site.
Para permitir que o bot da Auditoria do site da Semrush (SiteAuditBot) rastreie seu site, adicione o seguinte ao arquivo robots.txt:
User-agent: SiteAuditBot
Disallow:
(deixe um espaço em branco após “Disallow:”)
Confira um exemplo de um arquivo robots.txt:

Observe os diversos comandos baseados no user agent (rastreador) que o arquivo está tratando.
Esses arquivos são públicos e, para serem encontrados, devem ser hospedados no nível superior de um site. Para encontrar o arquivo robots.txt de um site, insira o domínio raiz dele seguido por /robots.txt no navegador. Por exemplo: o arquivo robots.txt do site Semrush.com pode ser encontrado em https://semrush.com/robots.txt.
Confira alguns termos que você pode ver em um arquivo robots.txt:
- User-Agent = rastreador da web para o qual você está dando instruções.
- Exemplos: SiteAuditBot, Googlebot
- Allow = comando (apenas para o Googlebot) que informa ao bot que ele pode rastrear uma página ou área específica de um site, mesmo se a página ou pasta pai não for permitida.
- Disallow = comando que informa ao bot para não rastrear uma URL ou subpasta específica de um site.
- Exemplo: Disallow: /admin/
- Crawl Delay = comando que informa aos bots quantos segundos eles devem esperar antes de carregar e rastrear outra página.
- Sitemap = indica onde está o arquivo sitemap.xml de uma determinada URL.
- / = use o símbolo “/” após um comando disallow para indicar ao bot que ele não deve rastrear todo o seu site
- * = símbolo curinga que representa qualquer cadeia de caracteres possível em uma URL, usado para indicar uma área de um site ou todos os user agents.
- Exemplo: Disallow: /blog/* indica todas as URLs na subpasta blog de um site
- Exemplo: User-agent: * indica instruções para todos os bots
Saiba mais sobre as especificações do robots.txt no site do Google ou no blog da Semrush.
O seguinte código na página principal de um site nos diz que não temos permissão para indexar/seguir links nele e que nosso acesso está bloqueado.
<meta name="robots" content="noindex, nofollow" >
Ou uma página contendo pelo menos um das tags "noindex", "nofollow", "none" levará a um erro de rastreamento.
Para permitir que nosso bot rastreie essa página, remova as tags “noindex” do código da página. Para obter mais informações sobre a tag noindex, consulte este artigo de suporte do Google.
Para colocar o bot na lista de permissões, entre em contato com seu webmaster ou provedor de hospedagem e peça para colocarem SiteAuditBot na lista de permissões.
Os endereços IP do bot são 85.208.98.128/25 (uma subrede usada somente pela Auditoria do site)
O bot usa as portas HTTP 80 e HTTPS 443 padrão para se conectar.
Se você usar quaisquer plug-ins (Wordpress, por exemplo) ou CDNs (redes de distribuição de conteúdo) para gerenciar seu site, também precisa adicionar o IP do bot à lista de permissões.
Para colocar um bot na lista de permissões do Wordpress, entre em contato com o suporte do Wordpress.
Veja alguns CDNs comuns que bloqueiam nosso rastreador:
- Cloudflare – veja como colocar o nosso bot na lista de permissões aqui
- Imperva – veja como colocar o nosso bot na lista de permissões aqui
- ModSecurity – veja como colocar o nosso bot na lista de permissões aqui
- Sucuri – veja como colocar o nosso bot na lista de permissões aqui
Observação: se você tiver hospedagem compartilhada, talvez seu provedor de hospedagem não permita que você coloque bots na lista de permissões ou edite o arquivo robots.txt.
Provedores de hospedagem
Confira abaixo uma lista de alguns dos provedores de hospedagem mais populares na web e como colocar um bot na lista de permissões de cada um deles ou como entrar em contato com a equipe de suporte para solicitar ajuda:
- Siteground – instruções de como adicionar à lista de permissões
- 1&1 IONOS – instruções de como adicionar à lista de permissões
- Bluehost* – instruções de como adicionar à lista de permissões
- Hostgator* – instruções de como adicionar à lista de permissões
- Hostinger – instruções de como adicionar à lista de permissões
- GoDaddy – instruções de como adicionar à lista de permissões
- GreenGeeks – instruções de como adicionar à lista de permissões
- Big Commerce – é preciso entrar em contato com o suporte
- Liquid Web – é preciso entrar em contato com o suporte
- iPage – é preciso entrar em contato com o suporte
- InMotion – é preciso entrar em contato com o suporte
- Glowhost – é preciso entrar em contato com o suporte
- Hosting – é preciso entrar em contato com o suporte
- DreamHost – é preciso entrar em contato com o suporte
*Observação: essas instruções funcionam para HostGator e Bluehost se você tiver um site em VPS ou hospedagem dedicada.
Se o tamanho da sua página de destino ou o tamanho total dos arquivos JavaScript/CSS exceder 2 MB, nossos rastreadores não conseguirão processá-la devido a limitações técnicas da ferramenta.
Para saber mais sobre o que pode estar causando o aumento de tamanho e como resolver o problema, consulte este artigo do nosso blog.
Para ver quanto do seu orçamento de rastreamento atual foi usado, acesse Perfil – Informações de assinatura e procure “Páginas a rastrear” em “Meu plano”.
Dependendo do plano de assinatura, você pode rastrear um determinado número de páginas em um mês (orçamento de rastreamento mensal). Se você ultrapassar a quantidade de páginas permitidas pela assinatura, terá que comprar limites adicionais ou esperar até o próximo mês, quando os limites serão renovados.
Além disso, se for exibido o erro “Você atingiu o limite de execução simultânea de campanhas” durante a configuração, significa que você atingiu o número máximo de auditorias do site que podem ser executadas ao mesmo tempo no seu plano de assinatura.
Cada plano de assinatura inclui limites diferentes:
- Conta gratuita: 1 auditoria de site por vez
- Kit de ferramentas de SEO Pro: até 2 auditorias do site simultâneas
- Kit de ferramentas de SEO Guru: até 2 auditorias do site simultâneas
- Kit de ferramentas de SEO Business: até 5 auditorias do site simultâneas
Se o domínio não pôde ser resolvido pelo DNS, provavelmente significa que o domínio informado durante a configuração está offline. Normalmente, os usuários têm esse problema ao inserir um domínio raiz (exemplo.com) sem perceber que a versão do domínio raiz do site não existe, e é preciso informar a versão WWW do site (www.exemplo.com).
Para evitar esse problema, o proprietário do site pode adicionar um redirecionamento de “exemplo.com” não seguro para “www.exemplo.com” seguro que existe no servidor. Esse problema também pode ocorrer se o domínio raiz estiver protegido, mas a versão WWW não estiver. Nesse caso, você apenas teria que redirecionar a versão WWW para o domínio raiz.
Se a sua página inicial tiver links para o restante de site ocultos em elementos JavaScript, você precisa ativar a renderização em JS para que possamos lê-los e rastrear essas páginas. Esta função está disponível nos planos Guru e Business do Kit de ferramentas de SEO.
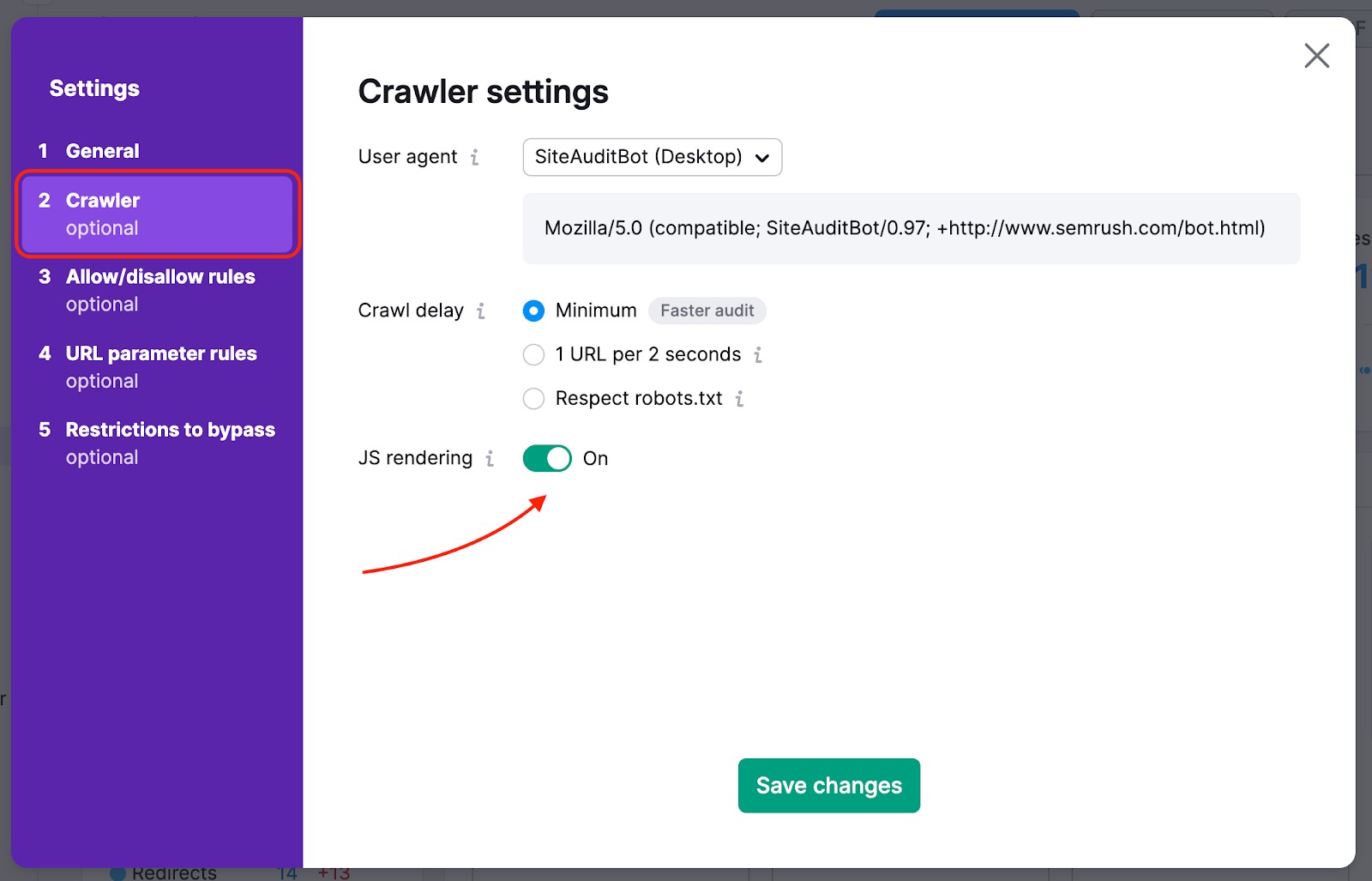
Para evitar que as páginas mais importantes do seu site não sejam rastreadas, você pode mudar a fonte de rastreamento de website para sitemap. Assim, os rastreadores não deixarão para trás nenhuma página que seja difícil de encontrar no site naturalmente durante a auditoria.
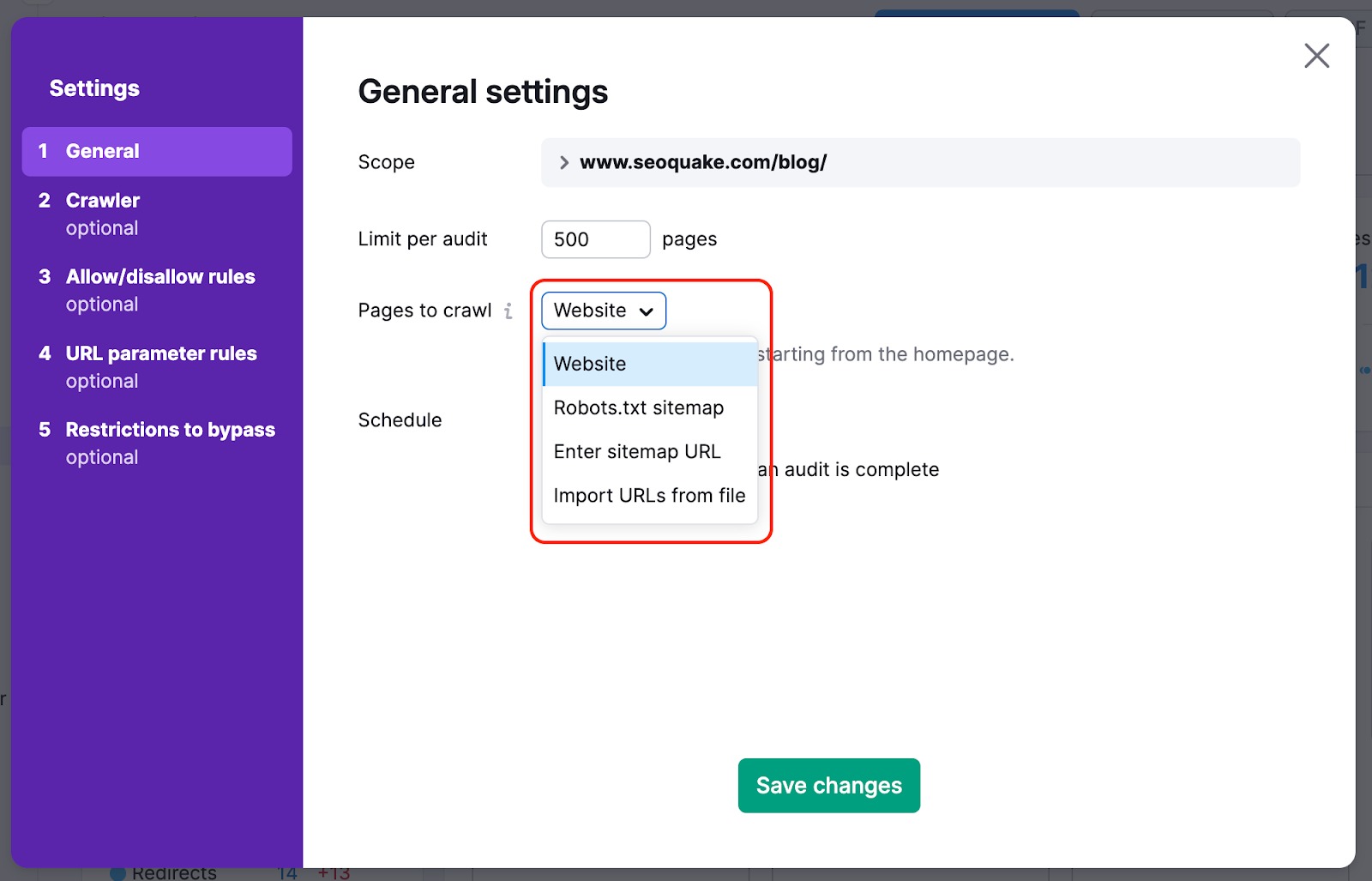
Também podemos rastrear o HTML de uma página que contém alguns elementos em JS e podemos analisar os parâmetros de arquivos JS e CSS com nossas verificações de desempenho.
Seu site pode estar bloqueando o SemrushBot no arquivo robots.txt. Você pode alterar o user agent de SemrushBot para GoogleBot, e provavelmente seu site permitirá o rastreamento do user agent do Google. Para fazer essa alteração, encontre a ícone de configurações em seu projeto e selecione User Agent.
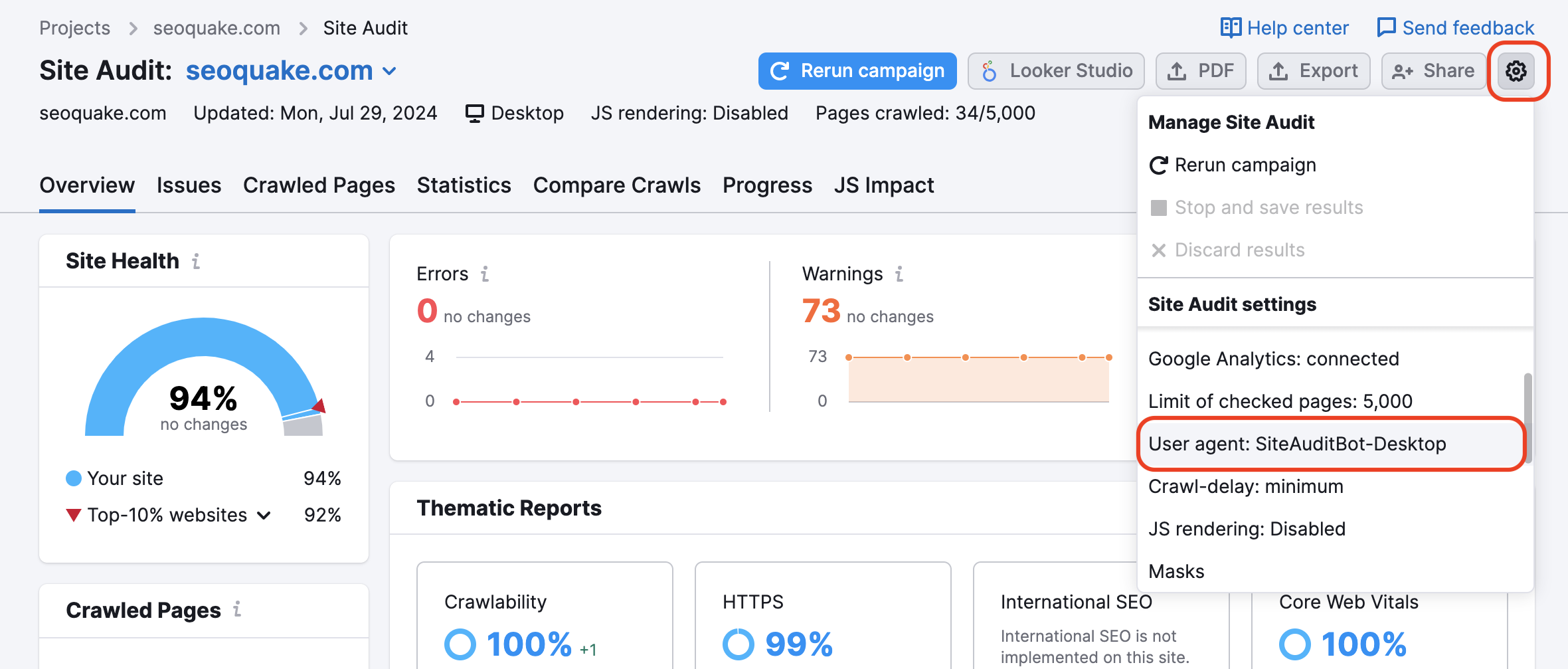
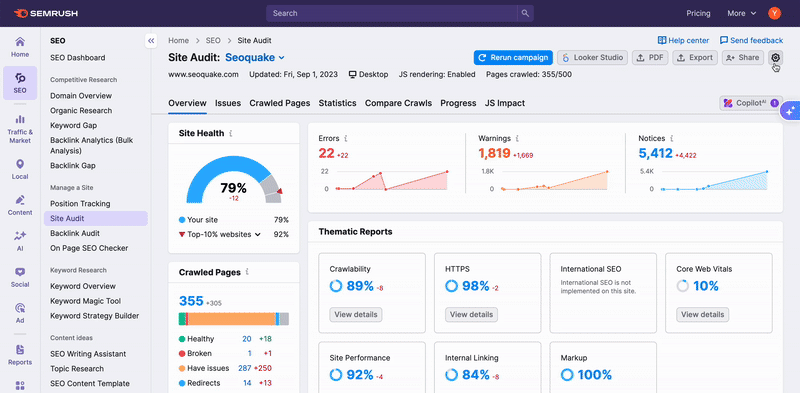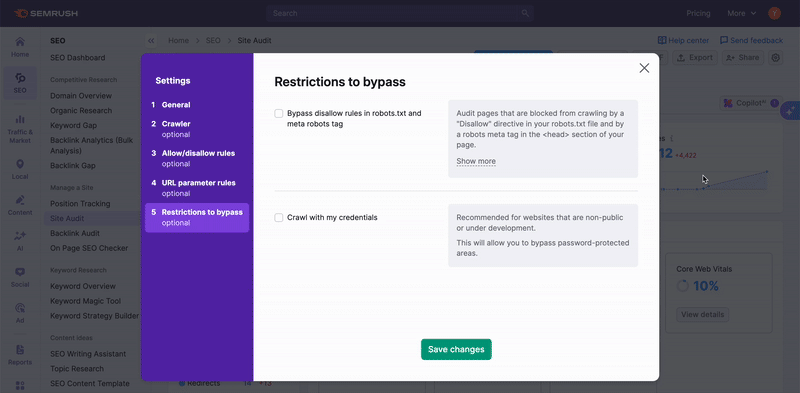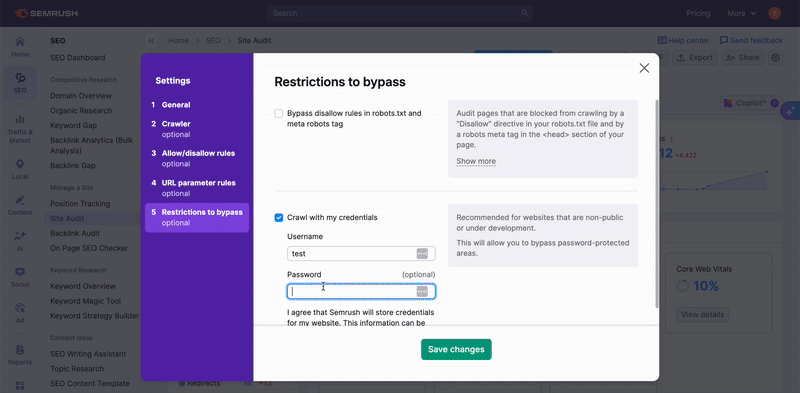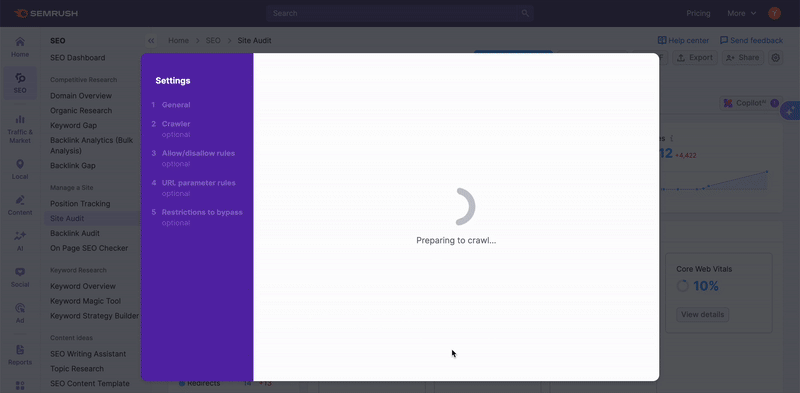
Se essa opção for usada, os recursos internos bloqueados e as páginas bloqueadas para rastreamentos não serão acionados. Lembre-se de que, para usar essa funcionalidade, a propriedade do site precisa ser verificada.
Isso é útil para sites que estão em manutenção. Também é útil quando o proprietário do site não deseja modificar o arquivo robots.txt.
Para auditar áreas privadas do site que são protegidas por senha, informe suas credenciais na opção “Rastreamento com suas credenciais” no ícone de engrenagem.
Isso é recomendável para sites em desenvolvimento ou que sejam privados e totalmente protegidos por senha.
“As configurações do rastreador foram alteradas desde a auditoria anterior. Isso pode influenciar os resultados da auditoria atual e o número de problemas detectados.”
Esta notificação é exibida na Auditoria do site após você atualizar qualquer configuração e executar a auditoria novamente. Isso não indica um problema, mas é apenas um aviso de que, se os resultados do rastreador mudam inesperadamente, esse é um dos prováveis motivos.
Confira nosso post no blog: Problemas de SEO comuns e como corrigi-los.