Quando você cria sua primeira pasta na Semrush, a Auditoria do site é configurada e iniciada automaticamente para o domínio informado. Para ver os resultados, acesse a ferramenta Auditoria do site pelo menu à esquerda ou pela página inicial assim que o rastreamento inicial for concluído.
Para pastas subsequentes que você criar, será necessário configurar a Auditoria do site manualmente. Para fazer isso, crie uma nova pasta na Auditoria do site e siga as instruções para configurar e iniciar sua campanha de auditoria.
Se você se deparar com algum problema ao executar a Auditoria do site, consulte Solução de problemas de Auditoria do site para obter ajuda.
Configurações gerais
Você será levado para a primeira parte do assistente de configuração, intitulada “Configurações gerais”. Agora, você pode optar por “Iniciar auditoria”, para executar imediatamente uma auditoria do seu site com nossas configurações padrão, ou prosseguir para personalizar as configurações de sua auditoria da forma como quiser. Mas não se preocupe, você sempre pode alterar as configurações e executar novamente a auditoria para rastrear uma área mais específica do site após fazer a configuração inicial.
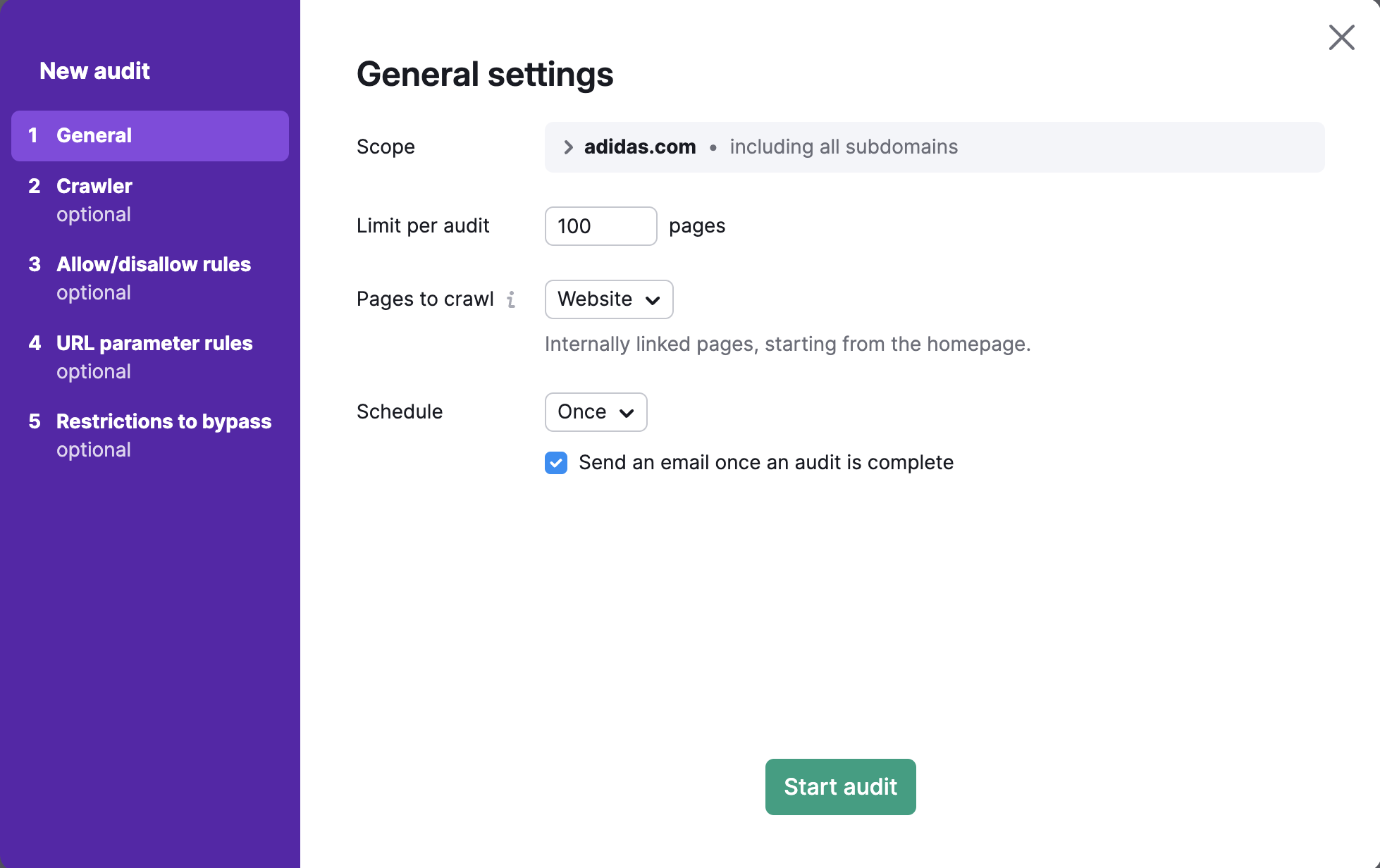
Escopo de rastreamento
Para rastrear um domínio, subdomínio ou subpasta específico, você pode inseri-lo no campo “Escopo”. Se você inserir um domínio neste campo, terá a opção de rastrear todos os subdomínios do seu domínio, basta ativar uma caixa de seleção.
Por padrão, a ferramenta verifica o domínio raiz, que inclui todos os subdomínios e subpastas disponíveis em seu site. Nas configurações da Auditoria do site, você especificar um subdomínio ou subpasta como escopo de rastreamento e desmarcar “Rastrear todos os subdomínios” se não quiser que outros subdomínios sejam rastreados.
Por exemplo, talvez você queira auditar somente o blog do seu site. Você pode especificar o escopo de rastreamento blog.semrush.com ou semrush.com/blog/, dependendo se ele está implementado como subdomínio ou subpasta.
Limite de páginas por auditoria
Em seguida, selecione quantas páginas você deseja rastrear por auditoria. Você deve escolher esse número de forma sensata, dependendo do nível da sua assinatura e com que frequência você planeja refazer a auditoria do site.
- Usuários do Kit de ferramentas de SEO Pro podem rastrear até 100.000 páginas por mês e 20.000 páginas por auditoria
- Usuários do Kit de ferramentas de SEO Guru podem rastrear 300.000 páginas por mês e 20.000 páginas por auditoria
- Usuários do Kit de ferramentas de SEO Business podem rastrear até 1 milhão de páginas por mês e 100.000 páginas por auditoria
Páginas a rastrear
Ao definir “Páginas a rastrear”, você determina como o robô da Auditoria do site da Semrush rastreia seu site e encontra páginas a serem auditadas. Além de definir a fonte de rastreamento, você pode definir máscaras e parâmetros para incluir ou excluir da auditoria nas etapas 3 e 4 do assistente de configuração.
Existem 4 opções para “Páginas a rastrear”: Site, Sitemap do robots.txt, Sitemap por URL e um arquivo de URLs.
1. Para a Fonte de rastreamento “Site”, vamos rastrear seu site como o GoogleBot, usando um algoritmo de pesquisa em largura (breadth-first) e navegando pelos links que vemos no código da sua página, começando pela página inicial.
Se você deseja rastrear apenas as páginas mais importantes de um site, optar por rastrear a partir do sitemap em vez do site permitirá que a auditoria rastreie as páginas mais importantes, em vez de escolher apenas as páginas mais acessíveis na página inicial.
2. Ao optar por Sitemap do robots.txt, rastrearemos apenas as URLs encontradas no sitemap incluído no arquivo robots.txt.
3. A Fonte de rastreamento “Sitemap por URL” é similar ao rastreamento a partir do “Sitemap do site”, mas essa opção permite informar especificamente a URL do seu sitemap.
Como os mecanismos de pesquisa usam sitemaps para entender quais páginas precisam rastrear, você deveria sempre tentar manter seu sitemap o mais atualizado possível e usá-lo como fonte de rastreamento com nossa ferramenta para obter uma auditoria precisa.
Observação: a Auditoria do site pode usar somente uma URL de sitemap como fonte de rastreamento em um dado momento, portanto, caso seu site tenha vários sitemaps, a opção seguinte (Importe URLs de um arquivo) pode ser uma solução alternativa.
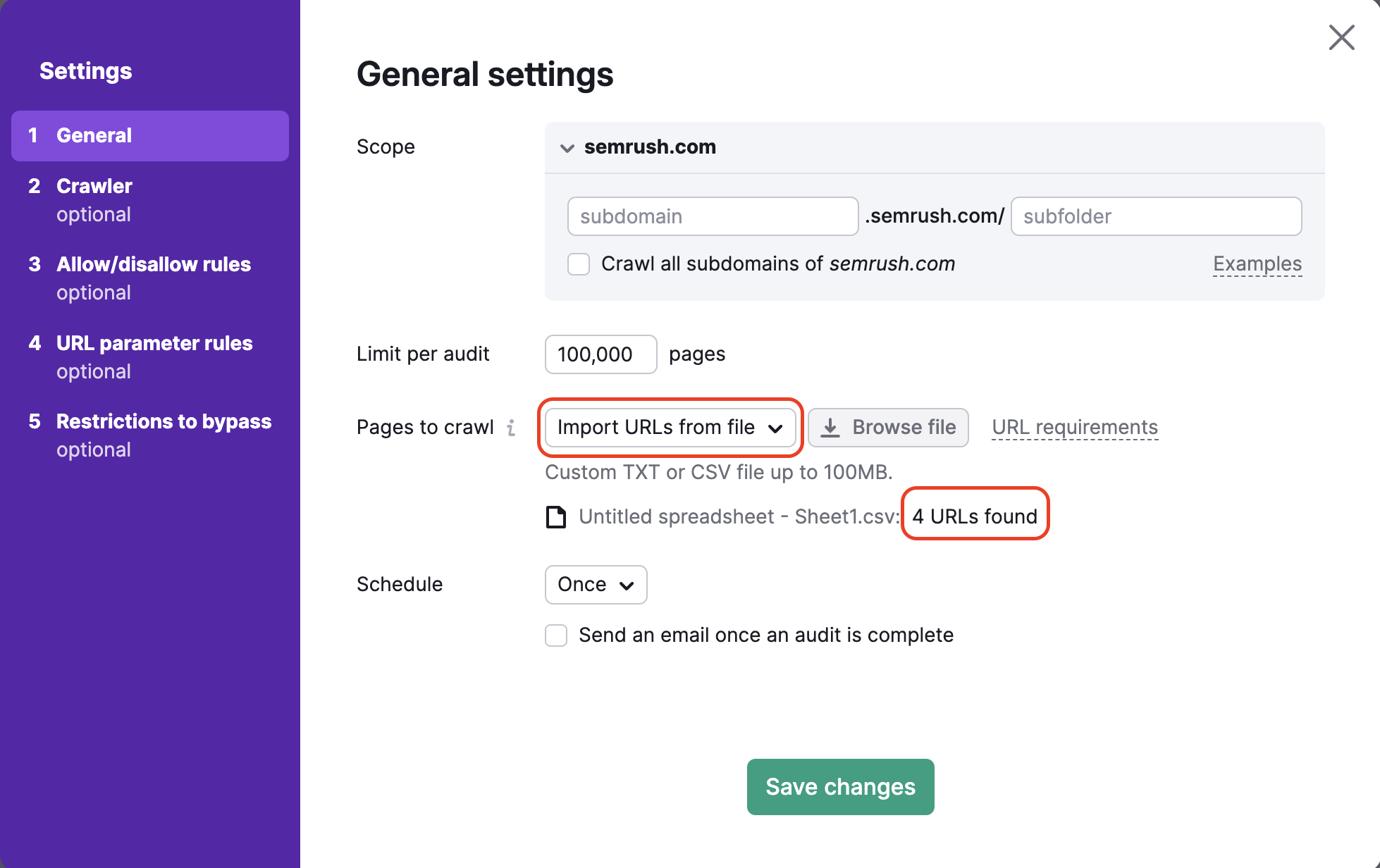
4. Para a Fonte de rastreamento “URLs do arquivo”, você audita um conjunto muito delimitado de páginas de um site. O seu arquivo deve estar formatado corretamente como .CSV ou .TXT, com uma URL por linha, e deve ser enviado diretamente à Semrush pelo seu computador.
Esse é um método útil se você quiser verificar páginas específicas e conservar seu orçamento de rastreamento. Se você tiver feito alguma alteração em apenas algumas páginas do seu site, pode usar esse método para executar uma auditoria específica e não desperdiçar seu orçamento de rastreamento.
Depois de carregar o arquivo, o assistente informará quantas URLs foram detectadas para que você possa verificar se deu certo antes de executar a auditoria.
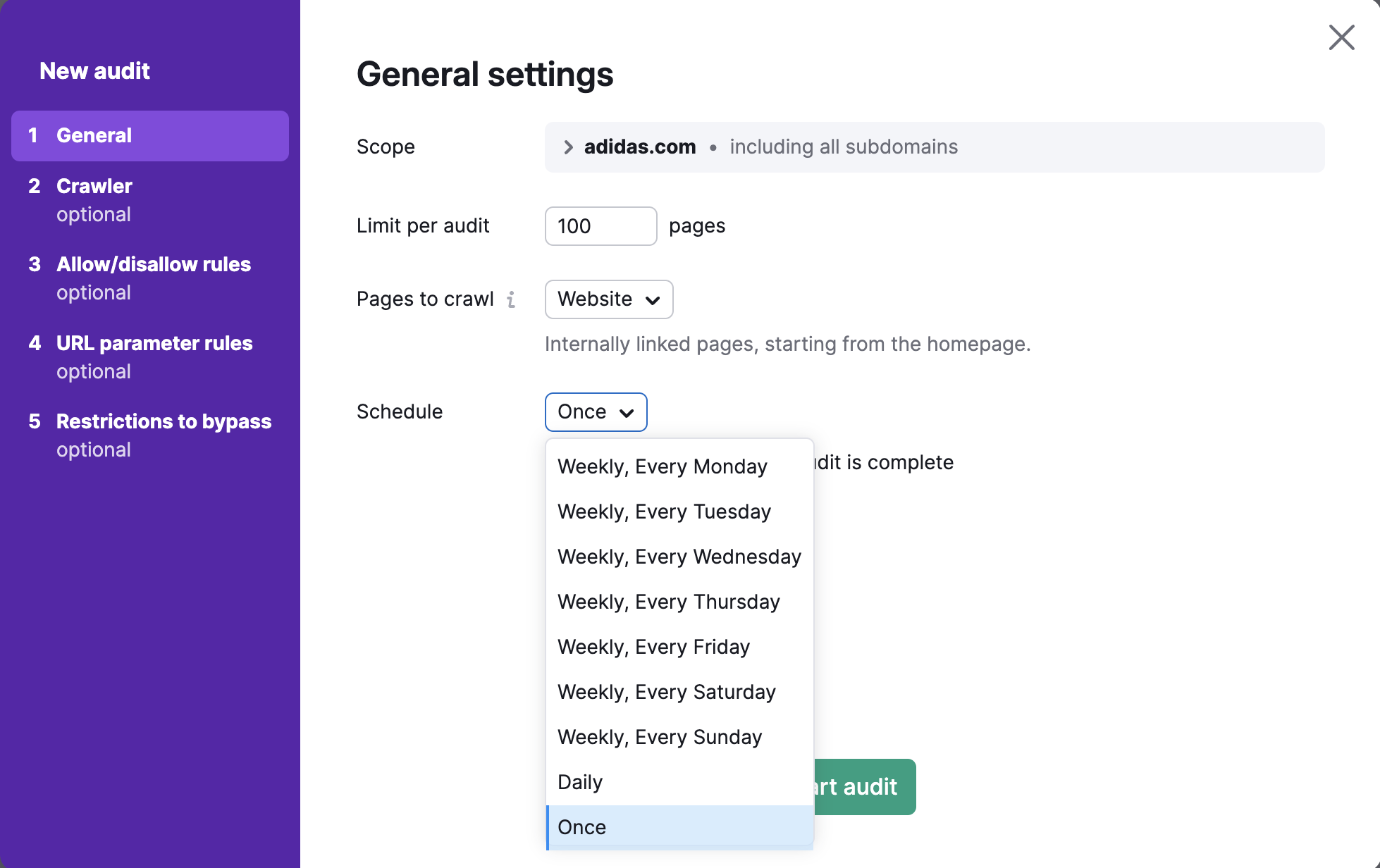
Agendar
Por fim, selecione com que frequência você deseja que façamos a auditoria do seu site automaticamente. As opções são:
- Semanalmente (escolha qualquer dia da semana)
- Diariamente
- Uma vez
Você pode executar a auditoria novamente quando desejar.
Depois de concluir todas as configurações desejadas, selecione “Iniciar auditoria”.
Configurações avançadas
Observação: as etapas de configuração a seguir são avançadas e opcionais.
Configurações do rastreador
É aqui que você pode escolher o user agent que vai rastrear seu site. Primeiro, defina o user agent de auditoria. Você pode escolher a versão Mobile (dispositivos móveis) ou Desktop (computadores) do SiteAuditBot ou do GoogleBot. Você também pode escolher o user agent OpenAI-Search, que verificará se o seu site pode ser rastreado pelo novo bot de pesquisa.
Por padrão, verificamos seu site com nosso bot de rastreamento para dispositivos móveis, que ajuda a auditar o site da mesma forma que o rastreador para dispositivos móveis do Google. Você pode alterar o bot para o rastreador para computadores da Semrush quando desejar.
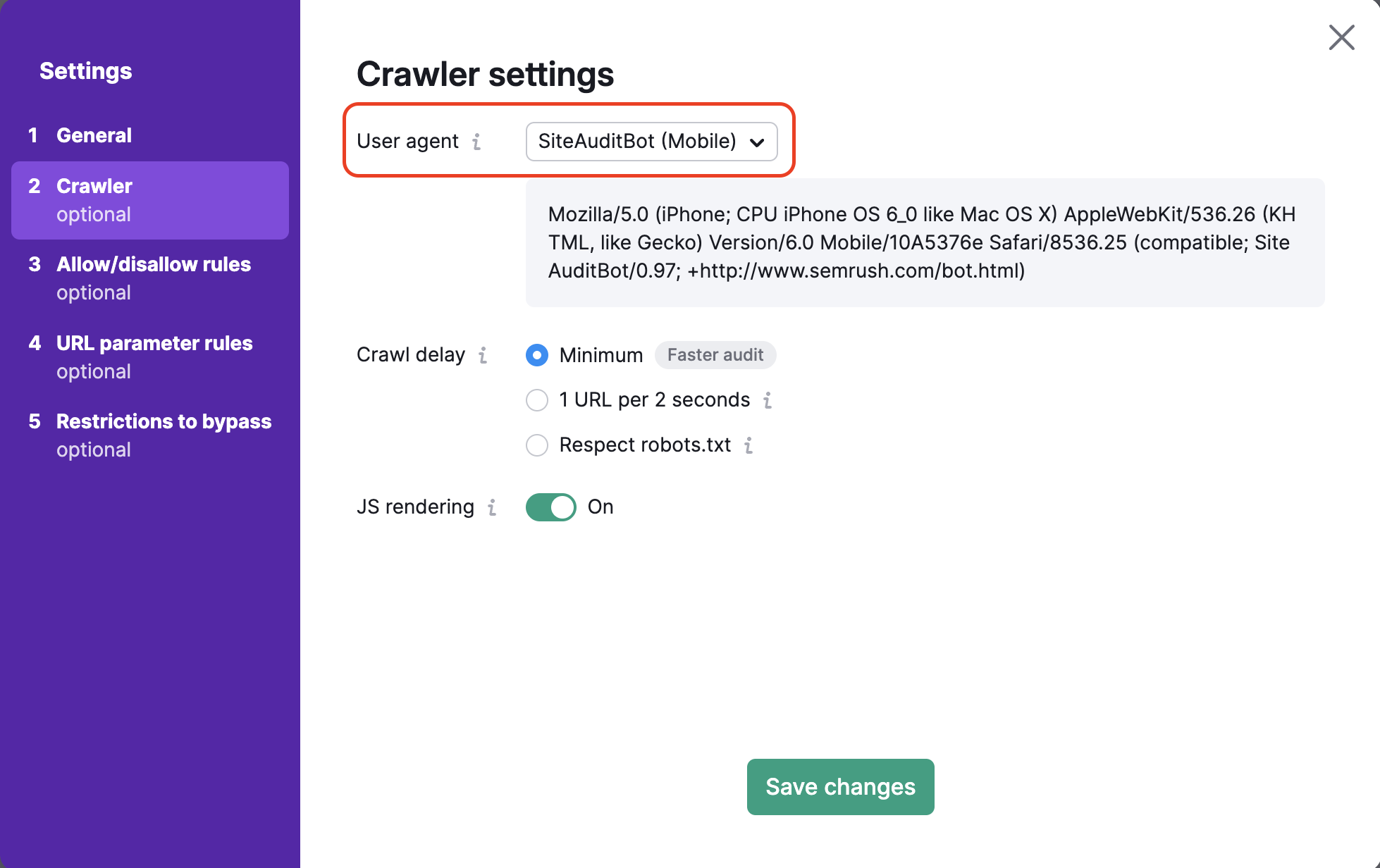
Conforme você altera o user agent, verá o código na caixa de diálogo abaixo mudar também. Esse é o código do user agent e pode ser usado em um comando curl se você quiser testar o user agent por conta própria.
Opções de crawl-delay (atraso de rastreamento)
Em seguida, você tem três opções para definir um atraso de rastreamento: atraso mínimo, respeitar o robots.txt e 1 URL a cada 2 segundos.
Se você deixar o atraso mínimo entre as páginas marcado, o bot rastreará seu site na velocidade normal. Por padrão, o SiteAuditBot aguardará um segundo antes de iniciar o rastreamento de outra página.
Se você tiver um arquivo robots.txt em seu site com um atraso de rastreamento especificado, poderá selecionar a opção “respeitar o robots.txt” para que nosso rastreador de auditoria do site siga essas instruções.
Veja abaixo um exemplo de atraso de rastreamento em um arquivo robots.txt:
Crawl-delay: 20
Se nosso rastreador deixar seu site mais lento e você não tiver uma diretiva de atraso de rastreamento no arquivo robots.txt, pode dizer à Semrush para rastrear 1 URL a cada 2 segundos. Dessa forma, a auditoria pode demorar mais para ser concluída, mas causará menos problemas de velocidade para usuários reais que estiverem usando o seu site durante a auditoria.
Rastreamento de JavaScript
Se você usar JavaScript em seu site, pode ativar Renderização em JS nas configurações da campanha de Auditoria do site. A renderização em JavaScript permite que o rastreador execute arquivos JS e veja o mesmo conteúdo que seus visitantes. Dessa forma, você consegue resultados de rastreamento mais precisos (muito semelhantes aos do Googlebot) e uma melhor visão da integridade do seu site.
Se a renderização em JS estiver desativada, a Auditoria do site verificará somente o HTML do seu site. Embora o rastreamento do HTML seja mais rápido e não prejudique o desempenho do seu site, os resultados da auditoria são menos precisos.

Essa função está disponível somente nos planos Guru ou Business do Kit de ferramentas de SEO.
Regras de Permitir/Proibir
Para rastrear subpastas específicas ou bloquear determinadas subpastas de um site, consulte a etapa de configuração Permitir/proibir URLs da Auditoria do site. Essa etapa também permite auditar diversas subpastas específicas ao mesmo tempo.
Inclua todo o conteúdo da URL que estiver após o TLD na caixa de texto abaixo. Por exemplo, se você quiser rastrear a subpasta http://www.example.com/shoes/mens/, precisa inserir “/shoes/mens/” na caixa de permissões à esquerda.
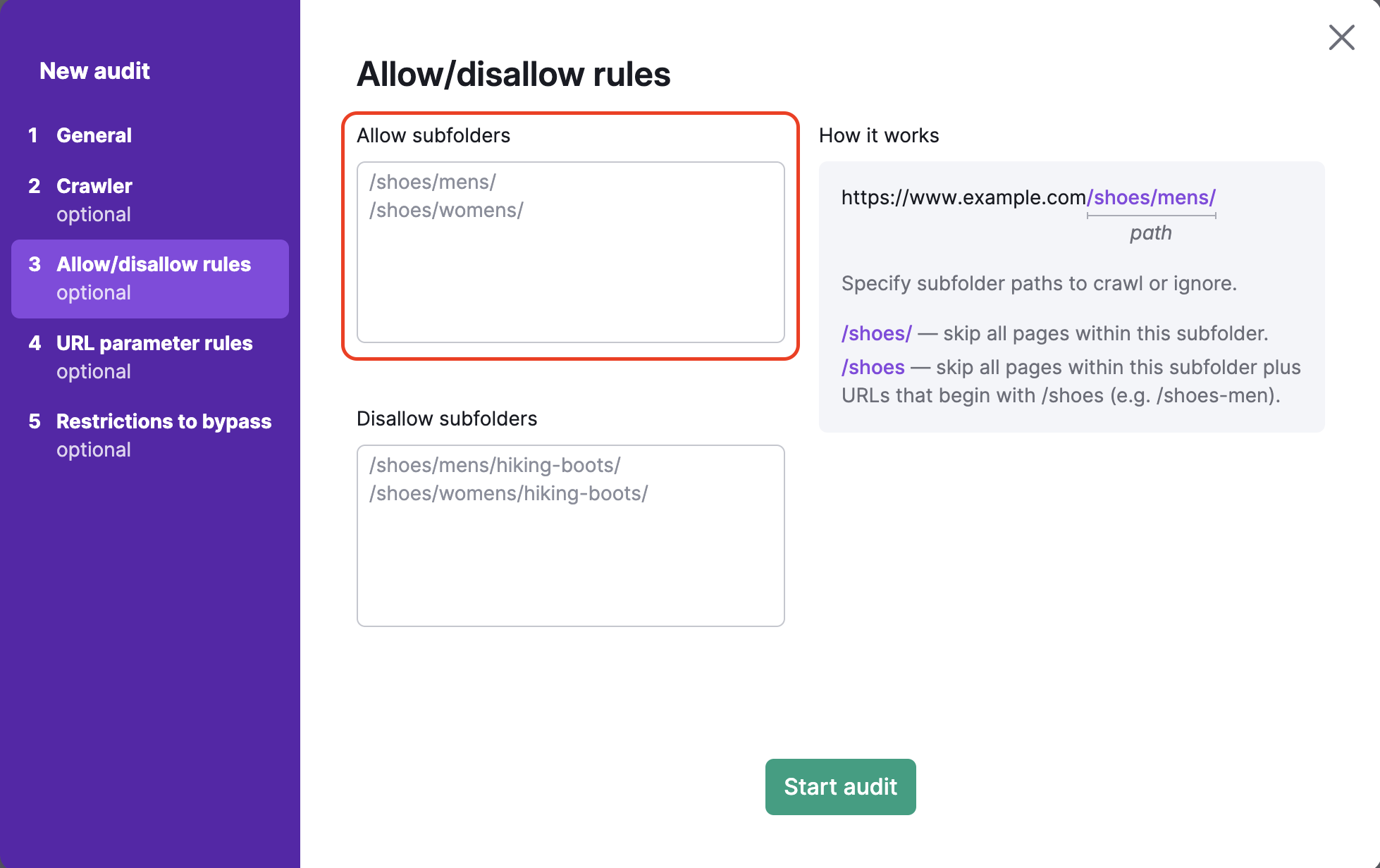
Para impedir o rastreamento de subpastas específicas, você deve inserir o caminho da subpasta na caixa de proibições. Por exemplo, para rastrear a categoria de sapatos masculinos, mas impedir o rastreamento da subcategoria botas para trilha em sapatos masculinos, (https://example.com/shoes/mens/hiking-boots/), você deve inserir /shoes/mens/hiking-boots/ na caixa de proibições.
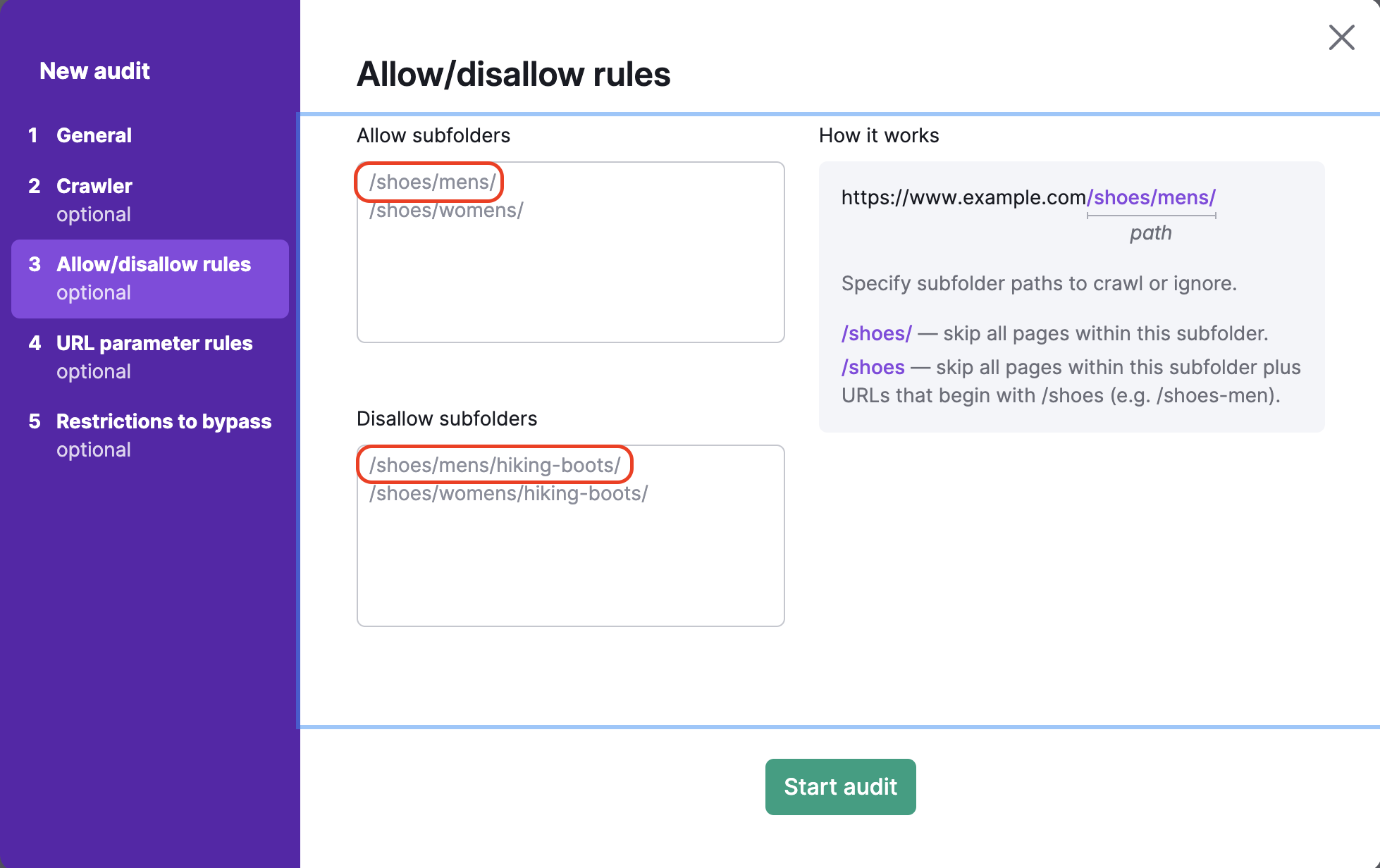
Caso você se esqueça de inserir o símbolo / no final da URL na caixa de proibição (exemplo: /shoes), a Semrush pulará todas as páginas na subpasta /shoes/, bem como todas as URLs que começam com /shoes (como www.example.com/shoes-men).
Regras de parâmetros de URL
Parâmetros de URL (também conhecidos como strings de consulta) são elementos de uma URL que não se encaixam na estrutura de caminho hierárquico. Em vez disso, eles são adicionados ao final de uma URL e fornecem instruções lógicas ao navegador da web.
Os parâmetros de URL sempre têm em um ? seguido pelo nome do parâmetro (page, utm_medium, etc) e =.
Portanto, “?page=3” é um parâmetro de URL simples que pode indicar a 3ª página de rolagem em uma única URL.
O 4º passo da configuração da Auditoria do site permite especificar os parâmetros de URL que seu site usa para removê-los das URLs durante o rastreamento. Isso ajuda a Semrush a evitar o rastreamento da mesma página duas vezes na auditoria. Se um bot vê duas URLs, uma com um parâmetro e outra sem, ele pode rastrear ambas as páginas e, consequentemente, desperdiçar seu orçamento de rastreamento.
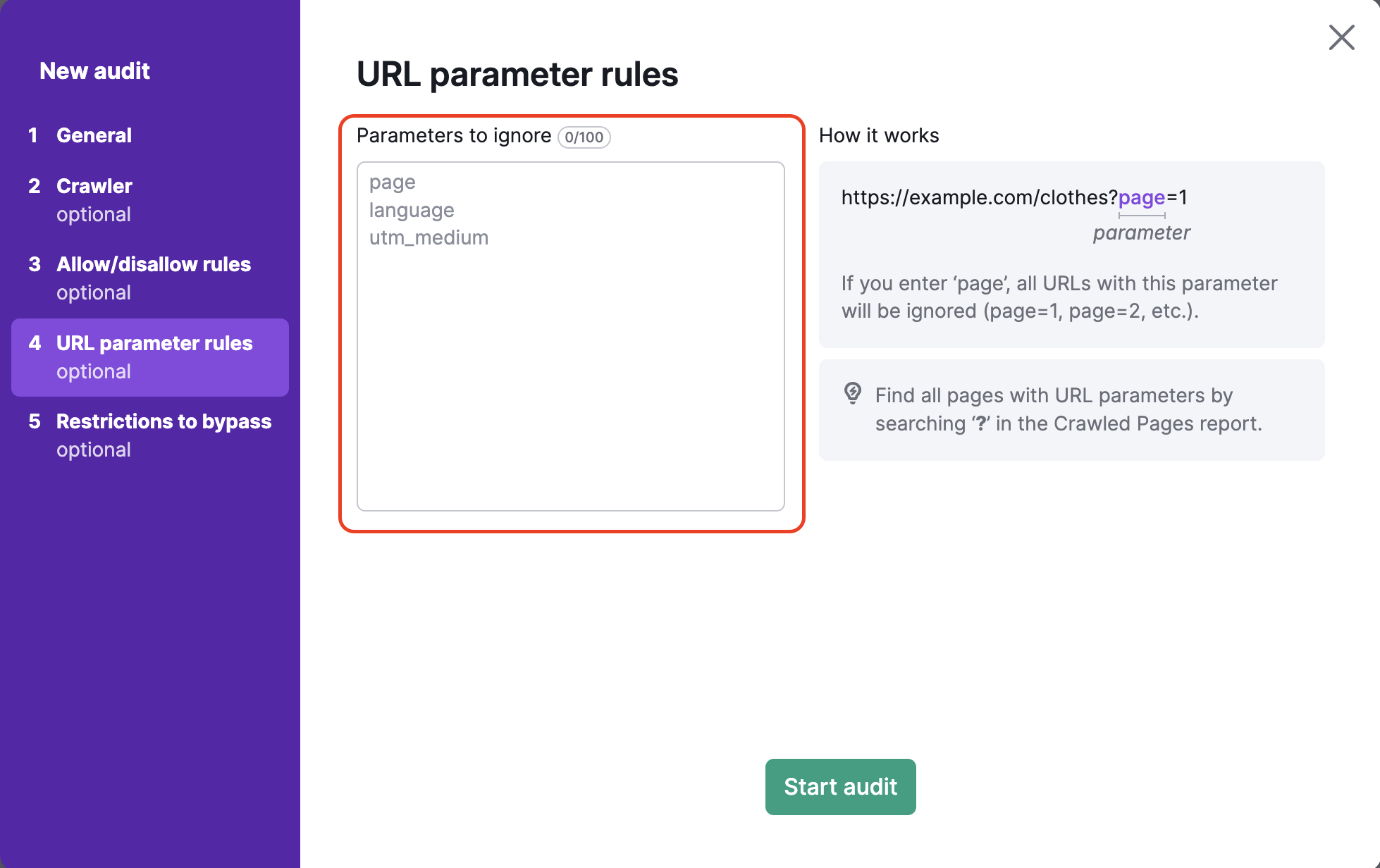
Por exemplo, se você adicionar “page” (página) a essa caixa, todas as URLs que tiverem “page” na extensão da URL serão removidas. Seriam URLs com valores como ?page=1, ?page=2, etc. Dessa forma, você evitaria o rastreamento da mesma página duas vezes (por exemplo, “/shoes” e “/shoes/?page=1” como uma URL) no processo de rastreamento.
Os usos comuns de parâmetros de URL incluem páginas, idiomas e subcategorias. Esses tipos de parâmetros são úteis para sites com grandes catálogos de produtos ou informações. Outro tipo de parâmetro de URL comum são os UTMs, usados para rastrear cliques e tráfego de campanhas de marketing.
Se você já tem uma campanha de Auditoria do site configurada e deseja alterar as configurações, pode fazê-lo pelo ícone de engrenagem de Configurações:
Você usará as mesmas instruções indicadas acima selecionando as opções “Máscaras” e “Parâmetros removidos”.
Restrições a ignorar
Para auditar um site em pré-produção ou oculto por autenticação com acesso básico, a etapa 5 oferece duas opções:
- Ignorar diretiva “Disallow” em robots.txt e pela meta tags robots
- Rastreamento com suas credenciais para acessar áreas protegidas por senha
Se você quiser ignorar os comandos de disallow no robots.txt ou meta tag (geralmente isso pode ser encontrado na tag
do seu site), você terá que fazer o upload do arquivo .txt fornecido pela Semrush para a pasta principal do seu site.Você pode fazer upload desse arquivo da mesma forma que faria upload de um arquivo para verificação do GSC, por exemplo, diretamente na pasta principal do seu site. Esse processo verifica que você é proprietário do site e permite que façamos o rastreamento.
Depois que o arquivo for carregado, você poderá iniciar a Auditoria do site e coletar os resultados.
Para rastrear com suas credenciais, basta digitar o nome de usuário e a senha que você usa para acessar a parte oculta do seu site. Em seguida, nosso robô utilizará suas informações de login para acessar as áreas ocultas e fornecer os resultados da auditoria.
Solução de problemas
Se a janela “auditoria do domínio falhou” for exibida, você precisa verificar se nosso rastreador de Auditoria do site não está bloqueado pelo seu servidor. Para garantir o rastreamento adequado, siga nossos passos de Solução de problemas de auditoria do site para incluir nosso bot na lista de permissões.
Como alternativa, você pode baixar o arquivo de log gerado quando ocorre falha no rastreamento e fornecê-lo ao seu webmaster para que ele possa analisar a situação e tentar descobrir o motivo pelo qual estamos sendo impedidos de rastrear.
Como conectar o Google Analytics à Auditoria do site
Após concluir o assistente de configuração, você poderá conectar a sua conta do Google Analytics para incluir problemas relacionados às suas páginas mais visualizadas.
Se algum problema persistir na execução da Auditoria do site, tente a Solução de problemas na Auditoria do site.