Como a Semrush transforma dados de tráfego em inteligência de tráfego
Talvez você tenha se perguntado de onde vem a inteligência de tráfego exibida no nosso Kit de ferramentas Tráfego e Mercado.
Este artigo explica os principais processos, desde a coleta de dados brutos até insights prontos para uso disponíveis nas ferramentas.
Basicamente, todos os dados passam por quatro etapas principais:
- Coleta de dados
- Limpeza de dados
- Modelagem de dados
- Entrega de dados
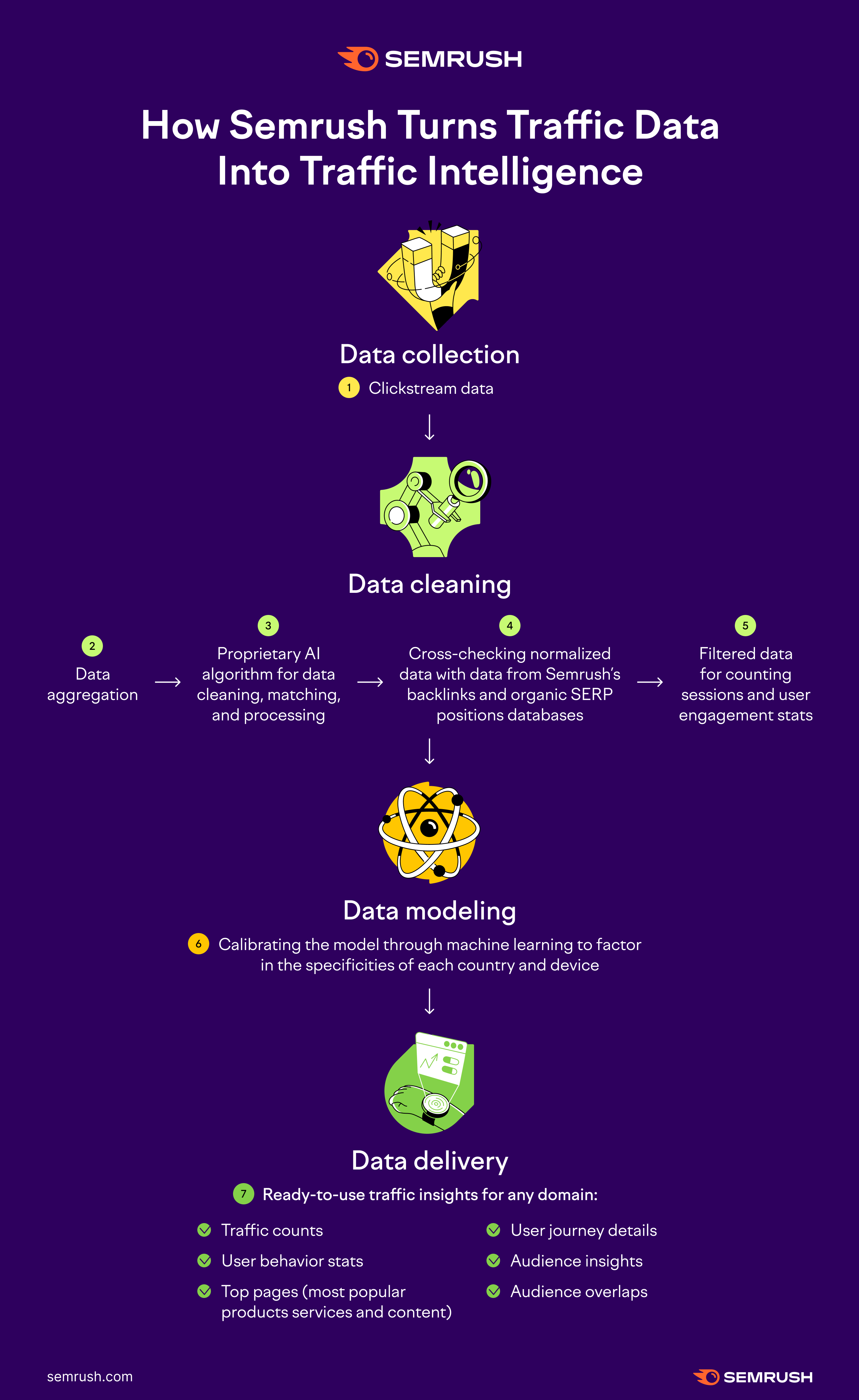
Coleta de dados
Recebemos terabytes de dados de vários provedores de dados a cada um ou dois dias. Isso é chamado de dados de sequências de cliques, ou seja, uma visualização agregada de milhões de jornadas online anônimas e reais de usuários da internet, acompanhando suas atividades online.
Os dados de sequência de cliques permitem identificar estatísticas e tendências gerais de comportamento dos usuários.
Limpeza de dados
Todos os dados são agregados e alinhados com um formato comum no sistema de análise de tráfego.
Usando nosso modelo exclusivo de aprendizado de máquina, eliminamos várias anomalias nos dados.
À medida que nossa IA aprende, começa a reconhecer padrões similares assim como faz o cérebro humano, transformando nosso modelo em um algoritmo extenso que consegue identificar anomalias e separar melhor dados questionáveis de dados representativos.
Também verificamos os dados no banco de dados de backlinks da Semrush e no banco de dados de posições orgânicas nas SERPs para conferir se correspondem às especificidades de cada país e dispositivo.
Depois que os dados são analisados pelo nosso algoritmo, temos um panorama mais realista das sessões de usuários comuns, e esse é o conjunto de dados usado para calcular nossas métricas de engajamento.
Modelagem e entrega de dados
Nesta etapa, temos uma caixa de big data em que armazenamos os dados de sequências de cliques e dados exclusivos.
Antes de inserirmos esses dados em nosso modelo de aprendizado de máquina, eles passam por mais uma verificação. Normalizamos os dados, levando em consideração a popularidade do domínio, assim como o comportamento “típico” do usuário em países, regiões demográficas, dispositivos e vários setores.
Por exemplo, é mais provável que um usuário dos EUA que usa a internet apenas uma vez por mês visite o Google (um domínio popular) do que o site da FDA (um domínio não tão visitado), então eliminamos a parte de usuários com padrões de atividade muito fracos para obter dados mais precisos para os sites mais populares e os menos visitados.
Assim, conseguimos inserir dados mais significativos em nosso modelo de aprendizado de máquina.
O algoritmo passa por aprendizado supervisionado, o que significa que nossa tecnologia de big data continua melhorando e aprendendo todos os dias.
Dados de tráfego diários e semanais
A Semrush oferece dados diários e semanais nos painéis de ferramentas de Tráfego e Mercado. Essa função aprimorada foi lançada junto com a adoção de um novo modelo de IA que conta com maior granularidade de tráfego, precisão e estabilidade.
Anteriormente, processávamos os dados apenas mensalmente, mas agora o modelo conta com processamento diário de dados. Como processamos dados diariamente, conseguimos fornecer métricas de tráfego diárias e semanais dos domínios de concorrentes.
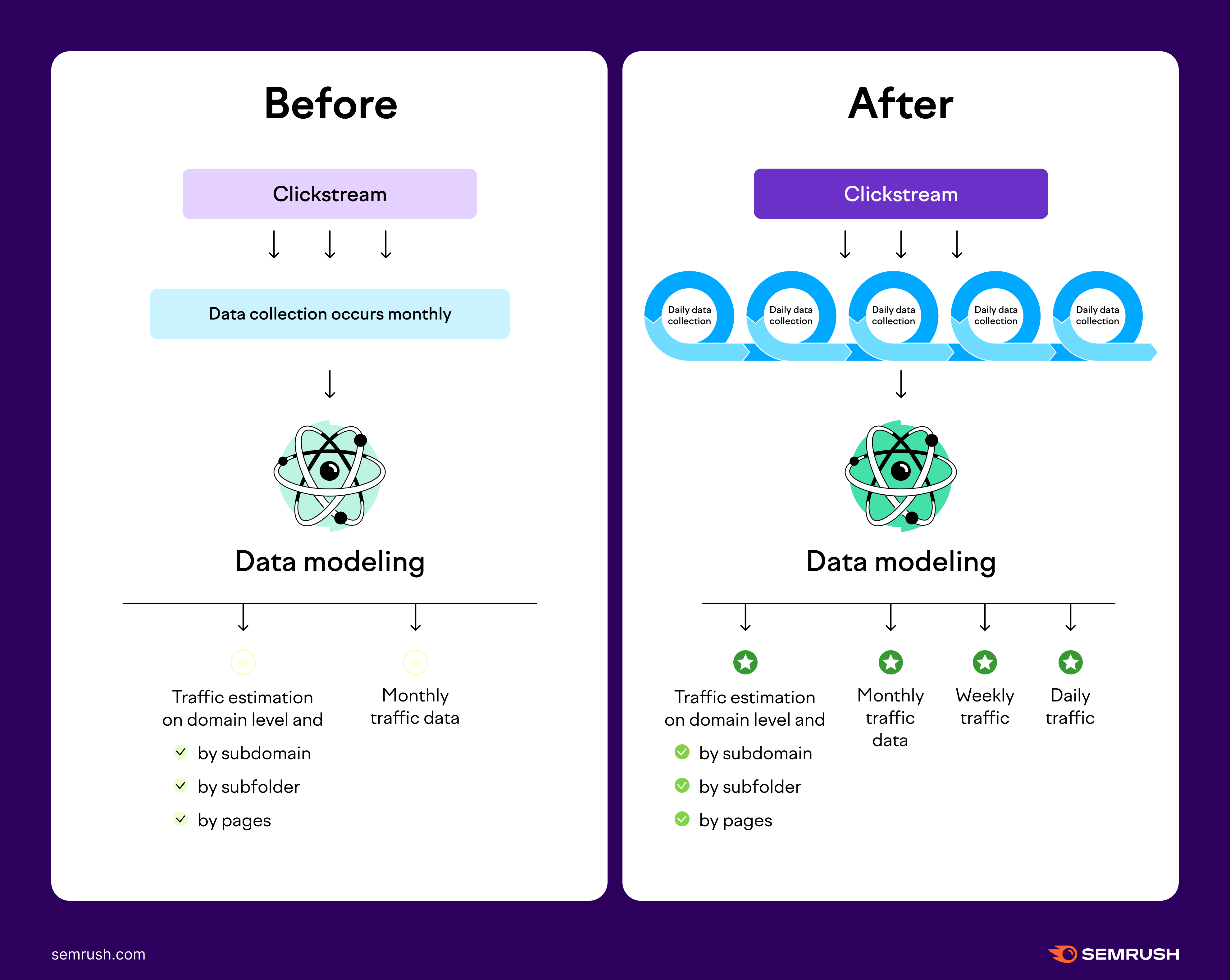
Com esse modelo de IA aprimorado, que oferece uma maior fidelidade de dados, conseguimos melhorar nossas estimativas anteriores, o que pode causar algumas variações nas métricas.
Sobre a cobertura de dados de tráfego da Semrush
Quando o assunto é a qualidade dos dados, o céu é o limite. Portanto, estamos trabalhando constantemente para adicionar novos dados às nossas ferramentas, enquanto nossa IA e a tecnologia de big data continuam aprendendo e aprimorando seus algoritmos.
Recentemente, atualizamos nosso modelo de processamento de dados para coletar insights de tráfego, o que nos permitiu expandir a cobertura de dados de tráfego em 20%.
Veja abaixou o que mudou exatamente.

*Eventos representam a visita de um usuário a uma determinada página.
**Sessões são um conjunto de ações realizadas por um usuário em um determinado site durante um período limitado. No Kit de ferramentas Tráfego e Mercado da Semrush, chamamos as sessões de visitas.