
O que é Robots.txt?
Robots.txt é um arquivo de texto com instruções para os robôs de mecanismos de pesquisa sobre quais páginas eles podem e não podem rastrear em um site.
Essas instruções são especificadas por “allow” (permitir) ou “disallow” (não permitir) o comportamento de determinas (ou todos) bots.
É assim que um arquivo robots.txt se parece:
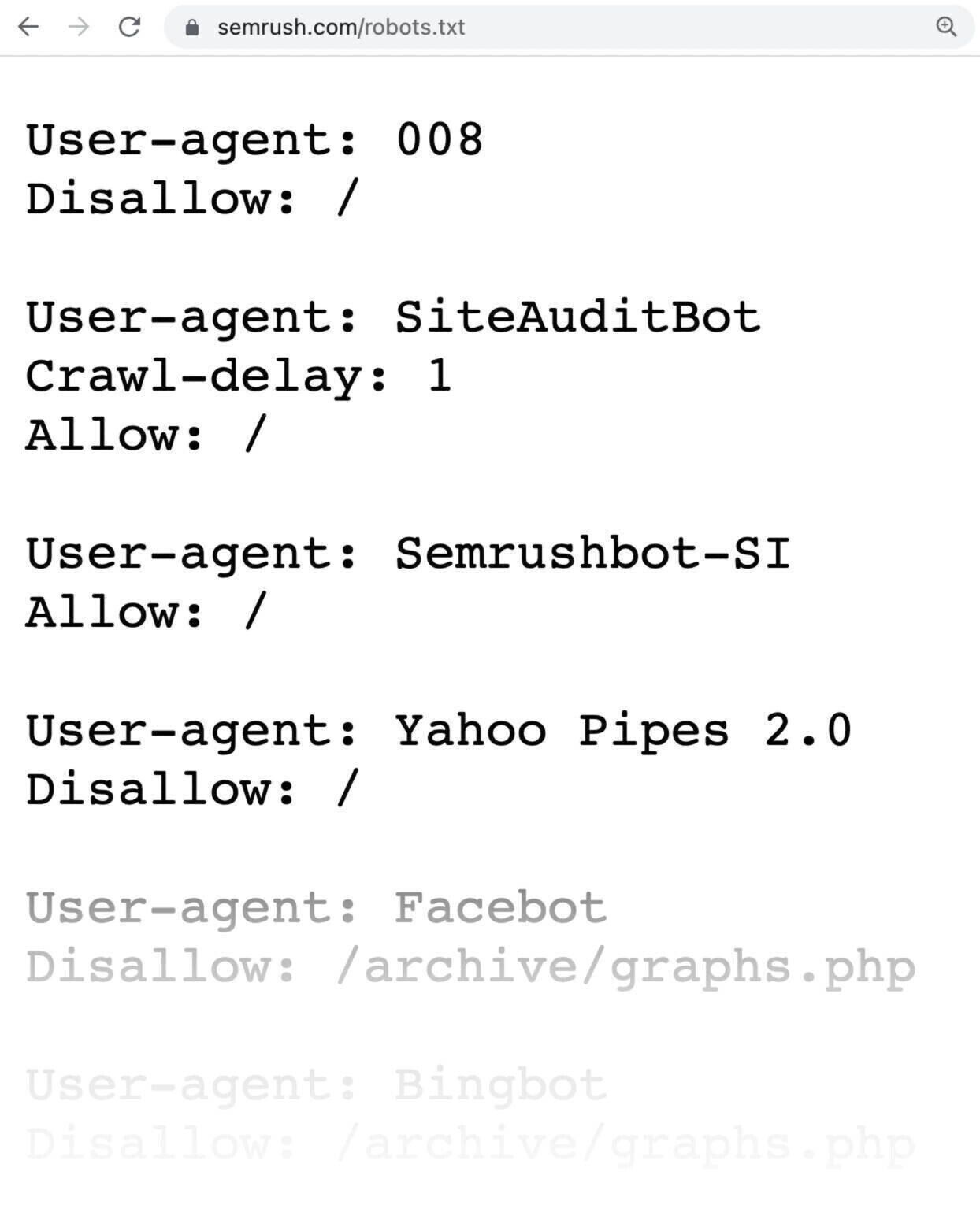
Os arquivos Robots.txt podem parecer complicados, mas a sintaxe (linguagem) é bastante simples.
Neste artigo veremos:
- Por que o arquivo Robots.txt é importante?
- Como funciona o arquivo Robots.txt?
- Como criar um arquivo Robots.txt
- Boas práticas para Robots.txt

Por que o arquivo Robots.txt é importante?
Um arquivo robots.txt ajuda a gerenciar as atividades dos rastreadores para que eles não sobrecarreguem seu site ou páginas que não devem ser exibidas.
Alguns motivos pelos quais você deve criar um arquivo robots.txt para o seu site são:
1. Otimizar o rastreamento
É preciso definir o número de páginas que o Google rastreará em seu site. Esse número pode variar com base no tamanho, integridade e backlinks do seu domínio.
Essa definição é importante porque, se o número de páginas for muito grande, algumas páginas no site podem não ser indexadas.
E as páginas que não são indexadas não classificam nos mecanismos de pesquisa.
Ao bloquear páginas desnecessárias com robots.txt, os rastreadores atêm-se às páginas mais importantes, não excedendo seu limite.
2. Bloquear páginas duplicadas e não que não devem ser públicas
Não é preciso (nem recomendado) permitir que os mecanismos de pesquisa rastreiem todas as páginas do seu site. Afinal, como vimos, nem todas elas precisam ser classificadas.
Os exemplos incluem sites de teste, páginas internas, páginas duplicadas ou de login.
O WordPress, por exemplo, desabilita automaticamente o /wp-admin/ – URL para acessar as ferramentas e gestão do site – para todos os rastreadores.
Essas páginas precisam existir, mas elas não precisam ser indexadas pelos mecanismos de busca nem encontradas pelos usuários.
3. Ocultar recursos
Às vezes, é importante indicar ao Google que se excluam recursos como PDFs, vídeos e imagens dos resultados da pesquisa.
Isso pode acontecer, por exemplo, quando você quer manter esses recursos privados ou fazer com que o Google se concentre em conteúdos mais importantes.
Nesses casos, usar o robots.txt é a melhor maneira de evitar que eles sejam indexados.
Como funciona o arquivo Robots.txt?
Os arquivos Robots.txt informam aos bots dos mecanismos de pesquisa quais URLs eles podem rastrear e, mais importante, quais não podem.
Os buscadores têm duas funções principais:
- Rastrear a web para descobrir conteúdo;
- Indexar conteúdos para que possam ser mostrados nos resultados de pesquisa.
À medida que os bots rastreiam a internet, eles descobrem e seguem novos links. Esse processo os leva do site A para o site B para o site C através de toda a web.
Quando chega a um site qualquer, a primeira coisa que um bot faz é procurar um arquivo robots.txt.
Se encontrar, o arquivo será lido antes que qualquer coisa seja feita.
Como falamos, a sintaxe é muito simples.
Você atribui regras a os rastreadores declarando seu agente de usuário (o bot do mecanismo de pesquisa) seguido por diretivas.
Você também pode usar o asterisco (*) para atribuir regras específica a cada agente do usuário. Ou seja, a diretiva se aplica a todos os bots, e não a um específico (Google, Bing etc.).
Por exemplo: este é o exemplo de um robots.txt com a instrução para permitir que todos os bots, exceto o DuckDuckGo, rastreiem seu site:

Observação: embora o arquivo robots.txt forneça instruções, ele não pode aplicá-las. É como um código de conduta. Bons bots (como os dos mecanismos de pesquisa) segues essas regras, mas rastreadores ruins (como os de spam) podem ignorá-las.
Como encontrar um arquivo Robots.txt
O arquivo robots.txt está hospedado no mesmo servidor do eu ite, assim como qualquer outro arquivo relacionado ao seu domínio.
Você pode ver o arquivo robots.txt de qualquer site digitando a URL completa da página inicial e adicionando /robots.txt.

Observação: o arquivo robots.txt deve estar sempre na raiz do seu domínio. Então, para o site www.exemplo.com.br, ele deve estar em www.exemplo.com.br/robots.txt. Se estive em qualquer outro lugar, e os rastreadores não o encontrarão e entenderão que você não tem um.
Sintaxe do arquivo Robots.txt
O arquivo robots.txt é composto por:
- Um ou mais blocos de diretivas;
- Cada bloco com um agente de usuário especificado;
- E uma instrução allow ou disallow.
User-agent: Googlebot
Disallow: /not-for-google
User-agent: DuckDuckBot
Disallow: /not-for-duckduckgo
Sitemap: https://www.seusite.com.br/sitemap.xmlA diretiva "User-agent"
A primeira linha de cada bloco de diretivas é o agente de usuário (“user-agent”), que identifica o rastreador a que ele se refere.
Então, se você quer informar ao Googlebot para não rastrear sua página de administração do WordPress, por exemplo, sua diretiva será:
User-agent: Googlebot
Disallow: /wp-admin/Lembre-se de que a maioria dos mecanismos de pesquisa possui vários rastreadores. Eles usam bots diferentes para seu os resultados "normais", imagens, vídeos etc.
Os buscadores sempre escolhem o bloco de diretivas mais específico que puderem encontrar.
Digamos que você tenha três conjuntos de diretivas: um para *, um para Googlebot e um para Googlebot-Image.
Se o agente de usuário do Googlebot-News rastrear seu site, ele seguirá as diretivas do Googlebot. Por outro lado, o user agent Googlebot-Image seguirá as diretivas mais específicas voltadas para ele.
Acesse este link para obter uma lista detalhada de rastreadores e seus diferentes agentes de usuário.
A diretiva "Disallow"
A segunda linha em qualquer bloco de diretivas é a linha “Disallow”.
Você pode ter várias diretivas de "não permitir" que especificam quais partes do seu site o rastreador não pode acessar.
Uma linha "Disallow" vazia significa que você não está desautorizando nenhuma página, então um rastreador pode acessar todas as seções do seu site.
Por exemplo: se você quiser permitir que todos os mecanismos de pesquisa rastreiem todo o seu site, seu bloco ficaria assim:
User-agent: *
Allow: /Por outro lado, se você quiser impedir que todos os bots rastreiem seu site, seu bloqueio ficaria assim:
User-agent: *
Disallow: /Diretivas como "Allow" e "Disallow" não diferenciam maiúsculas de minúsculas. No entanto, os valores dentro de cada diretiva, sim.
Por exemplo, /photo/ não é o mesmo que /Photo/.
Ainda assim, muitas vezes você encontrará as diretivas “Allow” e “Disallow” em maiúsculas porque torna o arquivo mais fácil para os humanos lerem.
A diretiva "Allow"
A diretiva “Allow” permite que os mecanismos de pesquisa rastreiem um subdiretório ou uma página específica, mesmo em um diretório não permitido.
Por exemplo: se você quiser impedir que o Googlebot acesse todos os posts do seu blog, exceto um específico, sua diretiva será assim:
User-agent: Googlebot
Disallow: /blog
Allow: /blog/examplo-de-postObservação: nem todos os mecanismos de busca reconhecem este comando. Google e Bing suportam esta diretiva.
A diretiva "Sitemap"
A diretiva “Sitemap” informa aos mecanismos de pesquisa, especificamente Bing, Yandex e Google, onde encontrar seu sitemap XML.
Os sitemaps geralmente incluem as páginas que você deseja que os mecanismos de pesquisa rastreiem e indexem.
Você pode encontrar essa diretiva na parte superior ou inferior de um arquivo robots.txt, como assim:
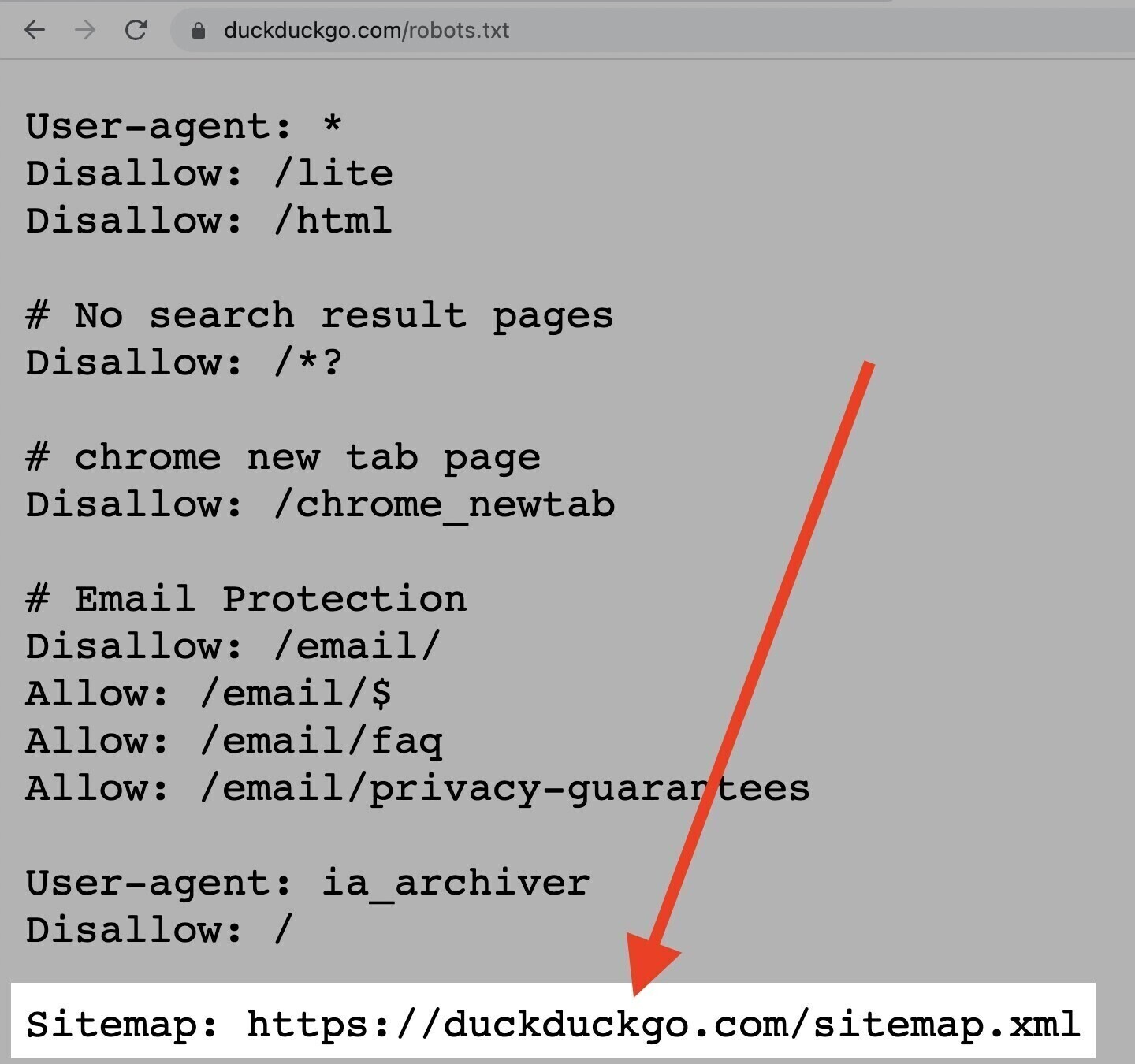
Dito isto, você pode (e deve) também enviar seu sitemap XML para cada mecanismo de pesquisa usando suas ferramentas para webmasters.
Os mecanismos de pesquisa rastrearão seu site eventualmente, mas o envio do sitemap acelera o processo de rastreamento. Se você não quiser que isso aconteça, adicione uma diretiva “Sitemap” ao seu arquivo robots.txt.
Diretiva "Crawl-delay"
A diretiva “crawl-delay” especifica um atraso de rastreamento em segundos. Ela serve para impedir que os bots sobrecarreguem um servidor, o que pode deixar seu site lento.
No entanto, o Google não oferece mais suporte a essa diretiva.
Se você quiser definir uma taxa de rastreamento para o Googlebot, precisará fazê-lo no Search Console. O Bing e Yandex, por outro lado, suportam a diretiva.
Funciona assim:
Se você quiser que um bot aguarde 10 segundos após cada ação de rastreamento, defina o atraso para 10:
User-agent: *
Crawl-delay: 10Diretiva "noindex"
O arquivo robots.txt informa a um bot o que ele pode ou não rastrear, mas não informa aos mecanismos de pesquisa quais URLs não devem ser indexadas e exibidas nos resultados da pesquisa.
A página ainda aparecerá na SERP, mas o bot não saberá o que está nela, então sua página ficará assim:

O Google nunca suportou oficialmente essa diretiva, mas os profissionais de SEO ainda acreditam que o Googlebot seguia as diretivas.
No entanto, em 1º de setembro de 2019, o Google deixou claro que esta diretiva não é suportada.
Se você deseja que uma página ou arquivo não apareça nos resultados da pesquisa, evite esta diretiva e use uma metatag robots noindex.
Como criar um arquivo Robots.txt
Se você ainda não tem um arquivo robots.txt, é muito fácil criar um.
Você pode usar uma ferramenta geradora de robots.txt ou você mesmo pode criar um do zero.
São quatro etapas:
- Crie o arquivo;
- Adicione as diretivas;
- Faça upload do arquivo no seu site;
- Teste.
1. Crie o arquivo Robots.txt
Abra um arquivo.txt com qualquer editor de texto ou navegador.
Observação: não use ferramentas como Word, pois elas geralmente salvam arquivos em um formato proprietário que pode adicionar caracteres aleatórios.
Em seguida, nomeie o documento como robots.txt. Ele deve ser nomeado assim para que funcione.
2. Adicione as diretivas
Um arquivo robots.txt consiste em um ou mais grupos de diretivas, e cada um deles consiste em várias linhas de instruções.
Cada grupo começa com um “User-agent” e possui as seguintes informações:
- A quem o grupo se aplica (o agente do usuário);
- Quais diretórios (páginas) ou arquivos o agente pode acessar;
- Quais diretórios (páginas) ou arquivos o agente não pode acessar;
- Um sitemap (opcional) para informar os mecanismos de pesquisa quais páginas e arquivos você considera importantes.
Os rastreadores ignoram as linhas que não correspondem a nenhuma dessas diretivas.
Por exemplo: digamos que você queira impedir o Google de rastrear seu diretório /clientes/ porque é apenas para uso interno.
O primeiro grupo ficaria assim:
User-agent: Googlebot
Disallow: /clientes/Se você tivesse mais instruções como esta para o Google, você as incluiria em uma linha separada logo abaixo, assim:
User-agent: Googlebot
Disallow: /clientes/
Disallow: /not-for-googleDepois de concluir as instruções específicas para o Google, você pode dar "enter" duas vezes para criar um novo grupo de diretivas.
Vamos fazer isso para todos os mecanismos de pesquisa e impedir que eles rastreiem seus diretórios /arquivo/ e /suporte/ porque eles são privados e apenas para uso interno.
Ficaria assim:
User-agent: Googlebot
Disallow: /clientes/
Disallow: /not-for-google
User-agent: *
Disallow: /arquivo/
Disallow: /suporte/Quando terminar, você pode adicionar seu sitemap.
Seu arquivo robots.txt finalizado ficaria assim:
User-agent: Googlebot
Disallow: /clientes/
Disallow: /not-for-google
User-agent: *
Disallow: /arquivo/
Disallow: /suporte/
Sitemap: https://www.seusite.com.br/sitemap.xmlObservação: os rastreadores lêem o arquivo de cima para baixo e registram o grupo de regras mais específico. Portanto, comece o arquivo robots.txt primeiro com agentes de usuário específicos e, em seguida, passe para o mais geral (*), que corresponde a todos os rastreadores.
3. Faça upload do arquivo no seu site
Depois de salvar seu arquivo robots.txt, suba-o no seu site e disponibilize-o para que os mecanismos de pesquisa rastreiem.
Infelizmente, não existe uma ferramenta que possa ajudar nessa etapa.
O upload do arquivo robots.txt depende da estrutura de arquivos do seu site e do serviço de hospedagem.
Pesquise on-line ou entre em contato com seu provedor para obter ajuda sobre como enviar seu arquivo robots.txt.
Por exemplo: você pode pesquisar por "upload arquivo robots.txt no WordPress" para encontrar instruções específicas.
Veja alguns posts que explicam como fazer upload do seu arquivo robots.txt nas principais plataformas:
- Robots.txt no WordPress
- Robots.txt no Wix
- Robots.txt no Joomla
- Robots.txt no Shopify
- Robots.txt no BigCommerce
Depois de fazer upload do arquivo, verifique se alguém pode vê-lo e se o Google pode lê-lo.
Aqui está como.
4. Teste
Primeiro, teste se o arquivo robots.txt está acessível publicamente (ou seja, se o upload foi feito corretamente).
Abra uma janela privada no seu navegador e procure seu arquivo robots.txt.
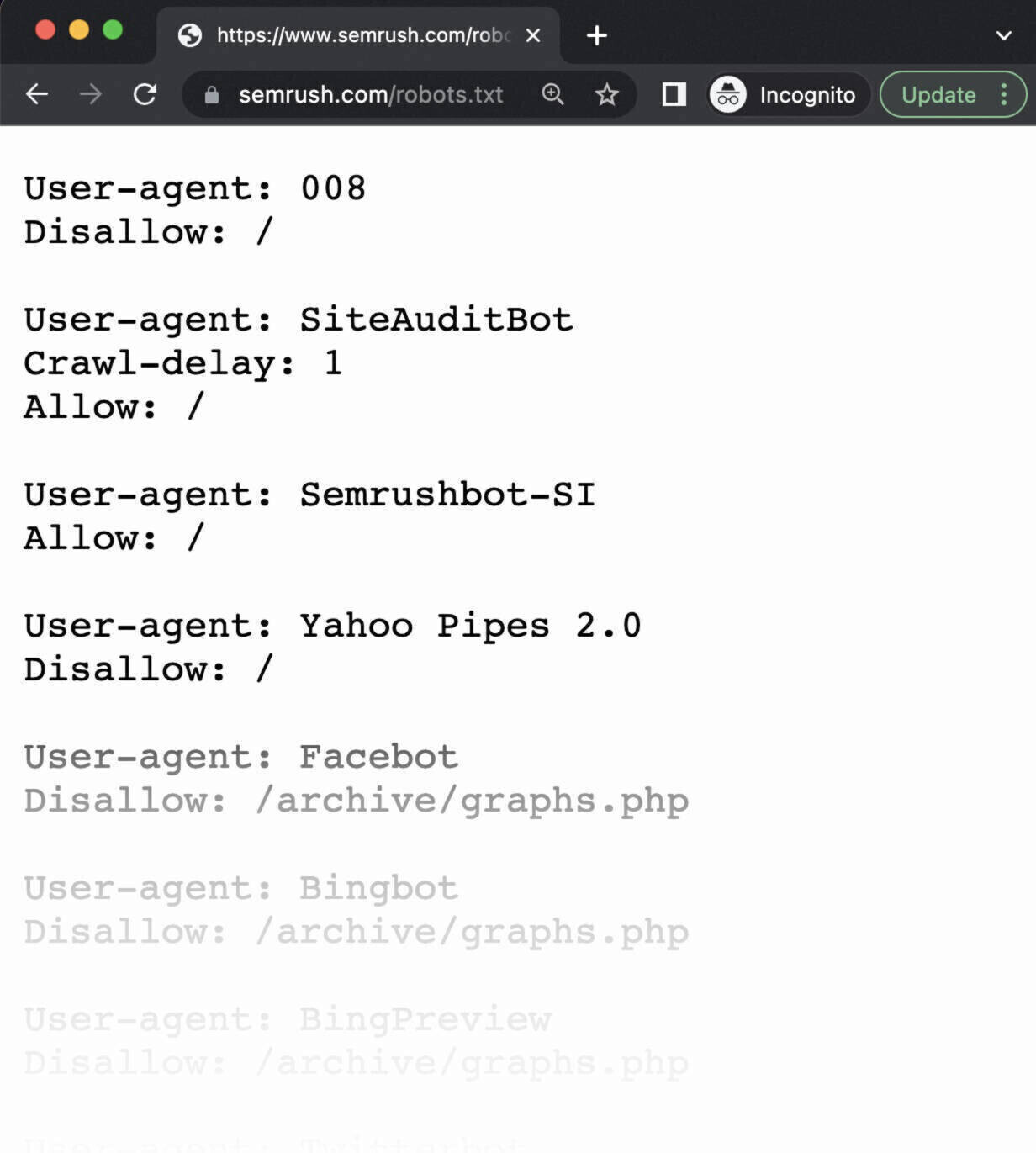
Se você vir o arquivo robots.txt com o conteúdo que você criou, pode passar para o teste de markup (código HTML).
O Google oferece duas opções para isso:
- A ferramenta Testar robots.txt no Search Console;
- A biblioteca robots.txt de código aberto.
Como a segunda opção é mais voltada para desenvolvedores avançados, foque em testar seu arquivo robots.txt no Google Search Console.
Observação: você deve ter uma conta configurada para usar a ferramenta.
Acesse o Testar robots.txt e clique para abrir.
Se você não vinculou seu site à sua conta do Google Search Console, será necessário adicionar uma propriedade.

Em seguida, você terá que verificar que é o proprietário do site.

Se você tiver propriedades verificadas, selecione na página inicial da ferramenta.

A ferramenta identificará quaisquer alertas de sintaxe ou erros de lógica.
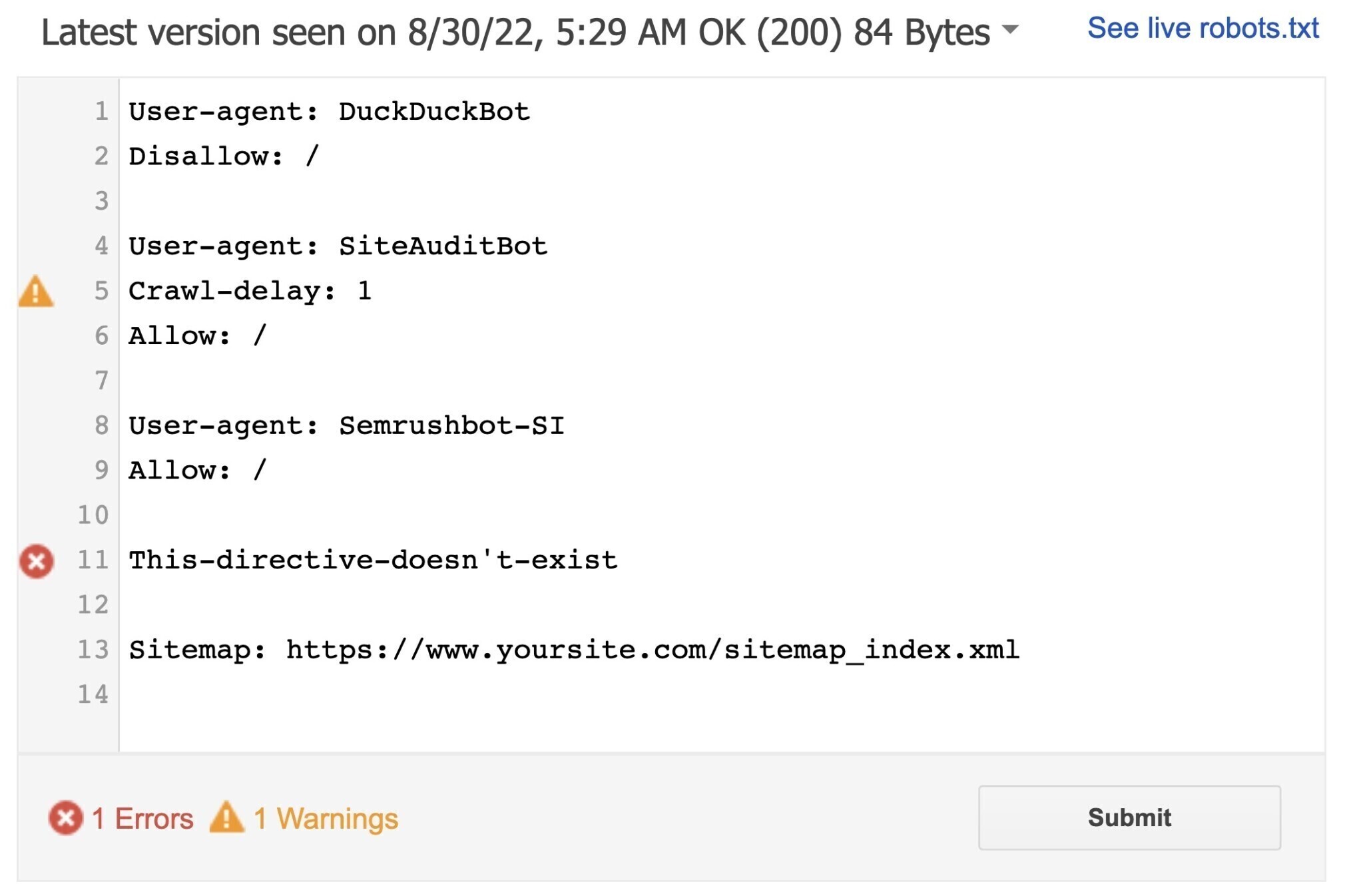
Você pode editar as advertências e erros diretamente na página e testar novamente quantas vezes forem necessárias.
Lembre-se de que as alterações feitas na página não serão salvas no seu site. A ferramenta não faz nenhuma alteração no arquivo real. Ele apenas testa a cópia hospedada nela.
Para implementar as alterações, copie e cole as mudanças no arquivo robots.txt do seu site.
Dica: configure auditorias mensais de SEO técnico com a ferramenta Auditoria de Site, da Semrush, para verificar novos problemas relacionados ao seu arquivo robots.txt. Monitorar o arquivo é importante, pois mesmo pequenas alterações podem afetar negativamente a indexabilidade do seu site.
Clique aqui para acessar a ferramenta Auditoria de Site.
Boas práticas para o arquivo Robots.txt
Lembre-se dessas práticas ao criar seu arquivo robots.txt para evitar erros comuns.
Use uma nova linha para cada diretiva
Cada diretiva deve ficar em uma linha. Caso contrário, os mecanismos de pesquisa não conseguirão lê-las e suas instruções serão ignoradas.
Ruim:
User-agent: * Disallow: /admin/
Disallow: /directory/Bom:
User-agent: *
Disallow: /admin/
Disallow: /directory/Use cada User-agent apenas uma vez
Os bots não se importam se você digitar o mesmo agente de usuário mais de uma vez.
Referenciá-los apenas uma vez ajuda a reduzir as chances de erro.
Ruim:
User-agent: Googlebot
Disallow: /exemplo-pagina
User-agent: Googlebot
Disallow: /exemplo-pagina-2Observe como o agente do usuário do Googlebot é listado duas vezes.
Bom:
User-agent: Googlebot
Disallow: /exemplo-pagina
Disallow: /exemplo-pagina-2No primeiro exemplo, o Google ainda seguiria as instruções e não rastrearia nenhuma das páginas.
Mas escrever todas as diretivas no mesmo User-agent ajuda você a se organizar.
Use o asterisco
Você pode usar o asterisco (*) para aplicar uma diretiva a todos os agentes do usuário e padrões de URL.
Por exemplo: se você quiser impedir que os mecanismos de pesquisa acessem URL com parâmetros, você pode listá-los um por um.
Ruim:
User-agent: *
Disallow: /tenis/vans?
Disallow: /tenis/nike?
Disallow: /tenis/adidas?Mas isso é ineficiente. Você pode simplificar suas rotas com um curinga.
Bom:
User-agent: *
Disallow: /tenis/*?O exemplo acima impede que todos os bots de mecanismos de pesquisa rastreiem todas as URLs na subpasta /shoes/ com um ponto de interrogação.
Use “$” para indicar o fim de uma URL
Adicionar o símbolo “$” indica o final de uma URL.
Por exemplo: se você deseja impedir que os mecanismos de pesquisa rastreiem todos os arquivos .jpg no seu site, você pode listá-los individualmente. Mas seria ineficiente.
Ruim:
User-agent: *
Disallow: /foto-a.jpg
Disallow: /foto-b.jpg
Disallow: /foto-c.jpgSeria muito melhor usar o recurso “$” assim:
Bom:
User-agent: *
Disallow: /*.jpg$Observação: neste exemplo, /cachorro.jpg não poderia ser rastreado, mas /cachorro.jpg?p=32414 poderia, porque não termina com “.jpg”.
A expressão “$” é um recurso útil em circunstâncias específicas, mas também pode ser arriscada. Então seja prudente.
Use a hashtag (#) para adicionar comentários
Os rastreadores ignoram tudo que começa com uma hashtag (#).
Os desenvolvedores geralmente usam uma hashtag para adicionar um comentário no arquivo robots.txt. Isso ajuda a manter o arquivo organizado e fácil de ler.
Para incluir um comentário, comece a linha com uma hashtag (#).
User-agent: *
#Landing Pages
Disallow: /landing/
Disallow: /lp/
#Files
Disallow: /files/
Disallow: /private-files/
#Websites
Allow: /website/*
Disallow: /website/search/*Os desenvolvedores ocasionalmente incluem mensagens engraçadas em arquivos robots.txt porque sabem que os usuários raramente as veem.
Por exemplo, o arquivo robots.txt do YouTube diz:
“Criado em um futuro distante (o ano 2000) após a revolta robótica em meados dos anos 90 que eliminou todos os humanos.”

O robots.txt da Nike diz “just crawl it' (uma piscadela para o slogan “just do it”) e também inclui seu logotipo.

Use arquivos Robots.txt para diferentes subdomínios
Os arquivos Robots.txt controlam apenas o comportamento de rastreamento no subdomínio em que estão hospedados.
Portanto, se você quiser controlar o rastreamento em um subdomínio diferente, precisará de um arquivo robots.txt separado.
Se seu site estiver no domínio.com e seu blog estiver no subdomínio blog.domínio.com, você precisará de dois arquivos robots.txt. Um para o diretório raiz do domínio principal e outro para o diretório raiz do seu blog.
Aprenda mais
Agora que você sabe como os arquivos robots.txt funcionam, separamos mais alguns artigos que você pode ler para aprender mais: